内容概要:

————————————
五、内存管理
29. 理解引用计数
- 从Mac OS X 10.8开始,“垃圾回收集器”(garbage collector)已经正式废弃了,以Objective-C代码编写Mac OS X程序时不应再使用它,而iOS则从未支持过垃圾收集
引用计数工作原理
- 在引用计数架构下,对象有个计数器,用以表示当前有多少个事物想令此对象继续存活下去。这在Objective-C中叫做“保留计数”(retain count),也叫
“引用计数”(reference count) - NSObject协议声明了下面三个方法用于操作计数器,以递增或递减其值:
retain:递增保留计数;release:递减保留计数;autorelease:待稍后清理“自动释放池”(autorelease pool)时,再递减保留计数 - 查看保留计数的方法叫做
retainCount,此方法不太有用,即便在调试时也如此,不推荐使用此方法 - 对象创建出来时,其保留计数至少为1。若想令其继续存活,则调用retain方法。要是某部分代码不再使用此对象,不想令其继续存活,那就调用release或autorelease方法。最终
当保留计数归零时,对象就回收了(deallocated),系统会将其占用的内存标记为“可重用”(reuse)。此时,所有指向该对象的引用也都变得无效了 ObjectB与ObjectC都引用了ObjectA。若ObjectB与ObjectC都不再使用ObjectA,则其保留计数降为0,于是便可摧毁了。还有其他对象想令ObjectB与ObjectC继续存活,而应用程序里又有另外一些对象想令那些对象继续存活。如果按
“引用树”回溯,那么最终会发现一个“根对象”(root object)。在Mac OS X应用程序中,此对象就是NSApplication对象;而在iOS应用程序中,则是UIApplication对象。两者都是应用程序启动时创建的单例1
2
3
4
5
6NSMutableArray *array = [[NSMutableArray alloc]init];
NSNumber *number = [[NSNumber alloc]initWithInt:111];
[array addObject:number];
[number release];
//do something with 'array'
[array release];由于代码中直接调用了release方法,所以在ARC下无法编译。在Objective-C中,调用alloc方法所返回的对象由
调用者所拥有。也就是说,调用者已通过alloc方法表达了想令该对象继续存活下去的意愿。不过请注意,这并不是说对象此时的保留计数必定是1。在alloc或“initWithInt:”方法的实现代码中,也许还有其他对象也保留了此对象,所以,其保留计数可能会大于1。能够肯定的是:保留计数至少为1。绝不应该说保留计数一定是某个值,只能说所执行的操作是递增了该计数还是递减了该计数创建完数组后,把number对象加入其中。
调用数组的“addObject:”方法时,数组也会在number上调用retain方法,以继续保留此对象。这时,保留计数至少为2。接下来,代码不再需要number对象了,于是将其释放。现在的保留计数至少为1。这样就不能照常使用number变量了。调用release之后,已经无法保证所指的对象仍然存活。当然,根据本例中的代码,我们显然知道number对象在调用了release之后仍然存活,因为数组还在引用着它。然而绝不应假设此对象一定存活,不要像下面这样编写代码:1
2
3
4NSNumber *number = [[NSNumber alloc]initWithInt:111];
[array addObject:number];
[number release];
NSLog(@"number=5@",number);即便上述代码在本例中可以正常执行,也仍然不是个好办法。如果调用release之后,基于某些原因,其保留计数降至0,那么number对象所占内存也许会回收,这样的话,再调用NSLog可能就将使应用程序崩溃了。这里说“可能”,是因为对象所占的内存在“解除分配”(deallocated)之后,只是放回“可用内存池”(avaliable pool)。如果执行NSLog时
尚未覆写对象内存,那么该对象仍然有效,这时程序不会崩溃。由此可见:因过早释放对象而导致的bug很难调试。为避免在不经意间使用了无效对象,一般调用完release之后都会清空指针。这就能保证不会出现可能指向无效对象的指针,这种指针通常称为
“悬挂指针”(dangling pointer)。比方说,可以这样编写代码来防止此情况发生:1
2
3
4NSNumber *number = [[NSNumber alloc]initWithInt:111];
[array addObject:number];
[number release];
number = nil;
属性存取方法中的内存管理
访问属性时,会用到相关实例变量的获取方法及设置方法。若属性为“strong关系”,则设置的属性值会保留,比方说,有个名叫foo的属性由名为_foo的实例变量所实现。那么该属性的设置方法会是这样:
1
2
3
4
5-(void)setFoo:(id)foo {
[foo retain];
[_foo release];
_foo = foo;
}此方法将
保留新值并释放旧值,然后更新实例变量,令其指向新值。顺序很重要。假如还未保留新值就先把旧值释放了,而且两个值又指向同一个对象,那么,先执行的release操作就可能导致系统将此对象永久回收。而后续的retain操作则无法令这个已经彻底回收的对象复生,于是实例变量就成了悬挂指针。
自动释放池
调用release会立刻递减对象的保留计数(而且还有可能令系统回收此对象),然后有时候可以不调用它,改为调用
autorelease,此方法会在稍后递减计数,通常是在下一次“事件循环”(event loop)时递减,不过也可能执行得更早些此特性很有用,尤其是在方法中返回对象时更应该用它。在这种情况下,我们并不总是想令方法调用者手工保留其值。比方说,有下面这个方法:
1
2
3
4-(NSString *)stringValue {
NSString *str = [[NSString alloc]initWithFormat:@"I am this: %@",self];
return str;
}此时返回的str对象其保留计数比期望值要多1(+1 retain count),因为调用alloc会令保留计数加1,而又没有与之对应的释放操作。保留计数多1,就意味着调用者要负责处理多出来的这一次保留操作。必须设法将其抵消。这并不是说保留计数本身就一定是1,它可能大于1,不过那取决于“initWithFromat:”方法内的实现细节。你要考虑的是如何将多出来的这一次保留操作抵消掉。
但是,不能在方法内释放str,否则还没等方法返回,系统就把该对象回收了。这里应该用autorelease,它会在稍后释放对象,从而给调用者留下了足够长的时间,使其可以在需要时先保留返回值。换句话说,此方法可以保证对象在跨越“方法调用边界”(method call boundary)后一定存活。实际上,释放操作会在清空最外层的自动释放池时执行,除非你有自己的自动释放池,否则这个时机指的就是当前线程的下一次事件循环。改写stringValue方法,使用autorelease来释放对象:
1
2
3
4-(NSString *)stringValue {
NSString *str = [[NSString alloc]initWithFormat:@"I am this: %@",self];
return [str autorelease];
}修改之后,stringValue方法把NSString对象返回给的调用者时,此对象必然存活。所以我们能够像下面这样使用它:
1
2NSString *str = [self stringValue];
NSLog(@“This string is: %@”,str);由于返回的str对象将于稍后自动释放,所以多出来的那一次保留操作到时自然就会抵消,无须再执行内存管理操作。因为自动释放池中的释放操作要等到下一次事件循环时才会执行,所以NSLog语句在使用str对象前不需要手工执行保留操作。但是,假如要持有此对象的话(比如将其设置给实例变量),那就需要保留,并于稍后释放:
1
2
3_instanceVariable = [[self stringValue]retain];
//…
[_instanceVariable release];由此可见,autorelease能延长对象生命期,使其在跨越方法调用边界后依然可以存活一段时间。
循环引用
使用引用计数机制时,经常要注意的一个问题就是
“循环引用”(retain cycle),也就是呈环状相互引用的多个对象。这将导致内存泄露,因为循环中的对象其保留计数不会降为0。对于循环中的每个对象来说,至少还有另外一个对象引用着它。在垃圾收集环境中,通常将这种情况认定为
“孤岛”(island of isoland)。此时,垃圾收集器会把三个对象全部回收走。而在Objective-C的引用计数架构中,则享受不到这一便利。通常采用“弱引用”来解决此问题,或是从外界命令循环中的某个对象不再保留另外一个对象。这两种办法都能打破循环引用,从而避免内存泄露。
要点
- 引用计数机制通过可以递增递减的计数器来管理内存。对象创建好之后,其保留计数至少为1。若保留计数为正,则对象继续存活。当保留计数降为0时,对象就被销毁了。
- 在对象生命期中,其余对象通过引用来保留或释放此对象。保留与释放操作分别会递增及递减保留计数
30. 以ARC简化引用计数
- Clang编译器项目带有一个
“静态分析器”,用于指明程序里引用计数出问题的地方。 - 使用ARC引用计数实际上还是执行的,只不过
保留与释放操作现在是由ARC自动添加。由于ARC会自动执行retain、release、autorelease等操作,所以直接在ARC下调用这些内存管理方法是非法的。具体来说,不能调用下列方法:retain、release、autorelease、dealloc ARC在调用这些方法时,并不通过普通的Objective-C消息派发机制,而是直接调用其底层C语言版本。这样做性能更好,因为保留及释放操作需要频繁执行,所以直接调用底层函数能节省很多CPU周期。比方说,ARC会调用与retain等价的底层函数objc_retain。这也是不能覆写retain、release或autorelease的缘由,因为这些方法从来不会直接被调用。
使用ARC时必须遵守的方法命名规则
- 将内存管理语义在方法名中表示出来早已成为Objective-C的惯例,而ARC则将之确立为硬性规定。这些规则简单地体现在方法名上。若方法名以下列词语开头,则其
返回的对象归调用者所有:alloc、new、copy、mutableCopy,归调用者所有的意思是:调用上述四种方法的那段代码要负责释放方法所返回的对象。 若方法名不以上述四个词语开头,则表示其所返回的对象并不归调用者所有。在这种情况下,返回的对象会自动释放,所以其值在跨越方法调用边界后依然有效。要想使对象多存活一段时间,必须令调用者保留它才行。
维系这些规则所需的全部内存管理事宜均有ARC自动处理,其中也包括在将其返回的对象上调用autorelease,下列代码演示了ARC的用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16+(EOCPerson *)newPerson {
EOCPerson *person = [[EOCPerson alloc]init];
return person;
//这个方法用new开头的,不需要在返回的时候retain、release或autorelease
}
+(EOCPerson *)somePerson {
EOCPerson *person = [[EOCPerson alloc]init];
return person;
//这个方法不是以拥有关系关键字开头的,所以ARC会自动在返回的时候加上autorelease
}
-(void)doSomething {
EOCPerson *personOne = [EOCPerson newPerson];
EOCPerson *personTwo = [EOCPerson somePerson];
//personOne是作为被这段代码拥有的关系返回的,所以需要release,
//personTwo不被这段代码拥有,不需要release
}除了会自动调用“保留”与“释放”方法外,使用ARC还可以执行一些手工操作很难甚至无法完成的优化。例如,在编译器,ARC会把能够互相抵消的retain、release、autorelease操作约简。如果发现在同一个对象上执行多次“保留”与“释放”操作,那么ARC有时可以成对地移除这两个操作。
- ARC可以在运行期监测到这一对多余的操作,也就是autorelease及紧跟其后的retain。为了优化代码,在方法中返回自动释放的对象时,要执行一个特殊函数。此时不直接调用对象的autorelease方法,而是改为调用
objc_autoreleaseReturnValue。此函数会检视当前方法返回之后即将要执行的那段代码。若发现那段代码在返回的对象上执行retain操作,则设置全局数据结构(此数据结构的具体内容因处理器而已)中的一个标志位而不执行autorelease操作。与之相似,如果方法返回了一个自动释放的对象,而调用方法的代码要保留此对象,那么此时不直接执行retain,而是改为执行objc_retainAutoreleaseReturnValue函数。此函数要检测刚才提到的那个标志位,若已经置位,则不执行retain操作。设置并检测标志位,要比调用autorelease和retain更快。 下面这段代码演示了ARC是如何通过这些特殊函数来优化程序的:
1
2
3
4
5
6
7
8+(EOCPerson *)personWithName:(NSString *)name {
EOCPerson *person = [[EOCPerson alloc]init];
person.name = name;
objc_autoreleaseReturnValue(person);
}
//Code using EOCPerson class
EOCPerson *tmp = [EOCPerson personWithName:@"Matt Galloway"];
_myPerson = objc_retainAutoreleaseReturnValue(tmp);为了求得最佳效果,这些特殊函数的实现代码都因处理器而异。下面这段伪代码描述了其中的步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16id objc_autoreleaseReturnValue(id object){
if(/*caller will retain object*/){
set_flag(object);
return object;///< no autorelease
}else{
return [object autorelease];
}
}
id objc_retainAutoreleaseReturnValue(id object){
if(get_flag(object)){
clear_flag(object);
return object;///< no retain
}else{
return [object retain];
}
}
变量的内存管理语义
ARC也会处理局部变量与实例变量的内存管理。默认情况下,每个变量都是指向对象的强引用。
1
2
3
4
5
6
7
8
9@interface EOCClass : NSObject
{
id _object;
}
@implementation EOCClass
-(void)setup{
_object = [EOCOtherClass new];
}
@end在手动管理引用计数时,实例变量_object并不会自动保留其值,而在ARC环境下则会这样做。也就是说,若在ARC下编译setup方法,则其代码会变为:
1
2
3
4
5-(void)setup{
id tmp = [EOCOtherClass new];
_object = [tmp retain];
[tmp release];
}当然,在此情况下,retain和release可以消去。所以,ARC会将这两个操作化简掉,于是,实际执行的代码还是和原来一样。不过,在编写设置方法时,使用ARC会简单一些。如果不用ARC,那么需要像下面这样来写:
1
2
3
4-(void)setObject:(id)object{
[_object release];
_object = [object retain];
}但是这样写会出问题。加入新值和实例变量已有的值相同,如果只有当前对象还在引用这个值,那么设置方法中的释放操作会使该值的保留计数降为0,从而导致系统将其回收。接下来再执行保留操作,就会令应用程序崩溃。使用ARC之后,就不可能发生这种疏失了。在ARC环境下,与刚才等效的设置函数可以这么写:
1
2
3-(void)setObject:(id)object{
_object = object;
}ARC会用一种安全的方式来设置:
先保留新值,再释放旧值,最后设置实例变量。在应用程序中,可用下列修饰符来改变局部变量与实例变量的语义:
- __stong:默认语义,保留此值
- __unsafe_unretained:不保留此值,这么做可能不安全,因为等到再次使用变量时,其对象可能已经回收了。
- __weak:不保留此值,但是变量可以安全使用,因为如果系统把这个对象回收了,那么变量也会自动清空。
- __autoreleasing:把对象“按引用传递”给方法时,使用这个特殊的修饰符。此值在方法返回时自动释放。
比方说,想令实例变量的语义与不使用ARC时相同,可以运用weak或unsafe_unretained修饰符:
1
2
3
4
5@interface EOCClass : NSObject
{
id __weak _weakObject;
id __unsafe_unretained _unsafeUnretainedObject;
}不论采用上面哪种写法,在设置实例变量时都不会保留其值。我们经常用__weak局部变量来打破循环引用。
ARC如何清理实例变量
- 使用ARC之后,不需要再编写像不使用ARC是的那种dealloc方法了,因为ARC借用Objective-C++的一项特性来生成清理例程。回收Objective-C++对象时,
待回收的对象会调用所有C++对象的析构函数(destructor)。编译器如果发现某个对象里含有C++对象,就会生成名为.cxx_destruct的方法。而ARC则借助此特性,在该方法中生成清理内存所需的代码。 不过,如果有非Objective-C的对象,比如CoreFoundation中的对象或是由malloc()分配在堆中的内存,那么仍然需要清理。然而不需要像原来那样调用超类的dealloc方法。ARC下不能直接调用dealloc方法。
ARC会自动在.cxx_destruct方法中生成代码并运行此方法。而在生成的代码中会自动调用超类的dealloc方法。ARC环境下,dealloc方法可以像这样写:1
2
3
4-(void)dealloc{
CFRelease(_coreFoundationObject);
free(_heapAllocatedMemoryBlob);
}因为ARC会自动生成回收对象时所执行的代码,所以通常无须再编写dealloc方法。
覆写内存管理方法
- 不使用ARC时,可以覆写内存管理方法。但是在ARC环境下不能这么做,因为会干扰到ARC分析对象生命期的工作。
要点:
- 有ARC之后,程序员就无须担心内存管理问题了。使用ARC来编程,可省去类中的许多“样板代码”。
- ARC管理对象声明周期的办法基本上就是:在合适的地方插入“保留”及“释放”操作。在ARC环境下,变量的内存管理语义可以通过修饰符指明,而原来则需要手工执行“保留”及“释放”操作。
- 由方法所返回的对象,其内存管理语义总是通过方法名来提现。ARC将此确定为开发者必须遵守的规则。
- ARC只负责管理Objective-C对象的内存。尤其要注意:CoreFoundation对象不归ARC管理,开发者必须实时调用CFRetain/CFRelease。
- 不要在属性名前面加上alloc、new、copy或mutableCopy,否则编译器会报错(Property follows Cocoa naming for returning ‘owned’objects)
31. 在dealloc方法中只释放引用并解除监听
对象在经历其生命期后,最终会为系统所回收,这时就要执行dealloc方法了,然后具体何时执行,则无法保证。不应该自己调用dealloc方法,运行期会在适当的生活调用它。
在dealloc方法中主要是要释放对象所拥有的引用,也就是说把所有Objective-C对象都释放掉,ARC会通过自动生成的.cxx_destruct方法,在dealloc中为你自动添加这些释放代码。对象所拥有的其他非Objective-C对象也要释放。比如CoreFoundation的对象就必须手工释放,因为它们是由纯C的API所生成的。
在dealloc方法中,通常还要把原来配置过的观测行为都清理掉。如果用NSNotificationCenter给此对象注册过某种通知,那么一般应该在这里注销,这样的话,通知系统就不再把通知发给回收后的对象了。
dealloc方法可以这样来写:
1 | -(void)dealloc { |
如果是手动管理引用计数的话,最后还要调用”[super dealloc]”,ARC会自动执行此操作。手动管理还要将当前对象所拥有的全部Objective-C对象逐个释放。
虽说应该于dealloc中释放引用,但是开销较大或系统内稀缺的资源则不在此列。像是文件描述符(file descriptor)、套接字(socket)、大块内存等,都属于这种资源。不能指望dealloc方法必定会在某个特定的时机调用,因为有一些无法预料的东西可能也持有此对象。通常的做法是,实现另外一个方法,当应用程序用完资源对象后,就调用此方法。
比方说,如果某个对象管理着连接服务器所用的套接字,那么也许就需要这种“清理方法”。此对象可能要通过套接字连接到数据库。
对于对象所属的类,其接口可以这样写:
1 | #import <Foundation/Foundation.h> |
该类与开发者之间的约定是:想打开连接,就调用“open:”方法;连接使用完毕,就调用close方法。“关闭”操作必须在系统把连接对象回收之前调用,否则就是编程错误,这与通过“保留”与“释放”操作来平衡引用计数是类似的。
在清理方法而非dealloc方法中清理资源还有个原因,就是系统并不保证每个创建出来的对象的dealloc都会执行。极个别情况下,当应用程序终止时,仍有对象处于存活状态,这些对象没有收到dealloc消息。由于应用程序终止之后,其占用资源也会返还给操作系统,所以实际上这些对象也就等于是消亡了。不调用dealloc方法是为了优化程序效率。在Mac OS X及iOS应用程序所对应的application delegate中,都含有一个会于程序终止时调用的方法。如果一定要清理某些对象,那么可在此方法中调用那些对象的“清理方法”。
在Mac OS X系统里,应用程序终止时会调用NSApplicationDelegate之中的下述方法:
1 | -(void)applicationWillTerminate:(NSNotification *)notification |
而在iOS系统里,应用程序终止时则会调用UIApplicationDelegate之中的下述方法:
1 | -(void)applicationWillTerminate:(UIApplication *)application |
如果对象管理着某些资源,那么在dealloc中也要调用“清理方法”,以防开发者忘了清理这些资源。下面举例说明close与dealloc方法应如何写:
1 | -(void)close{ |
编写dealloc方法时还需注意,不要在里面随便调用其他方法。无论在这里调用什么方法都不应该,因为对象此时“已近尾声”。如果在这里所调用的方法又要异步执行某些任务,或是又要继续调用它们自己的某些方法,那么等到那些任务执行完毕时,系统已经把当前这个待回收的对象彻底摧毁了。
调用dealloc方法的那个线程会执行“最终的释放操作”,令对象的保留计数降为0,而某些方法必须在特定的线程里(比方说主线程里)调用才行。若在dealloc里调用了那些方法,则无法保证当前这个线程就是那些方法所需的线程。通过编写常规代码的方式,无论如何都没办法保证其会安全运行在正确的线程上,因为对象处在“正在回收的状态”,为了指明此种情况,运行期系统已经改动了对象内部的数据结构。
在dealloc里也不要调用属性的存取方法,因为有人可能会覆写这些方法,并于其中做一些无法在回收阶段安全执行的操作。此外,属性可能正处于“键值观测”机制的监控之下,该属性的观察者可能会在属性改变时“保留”或使用这个即将回收的对象。这种做法会令运行期系统的状态完全失调,从而导致一些莫名其妙的错误。
要点:
- 在dealloc方法里,应该做的事情就是释放指向其他对象的引用,并取消原来订阅的“键值观察(KVO)”或NSNotificationCenter等通知,不要做其他事情。
- 如果对象持有文件描述符等系统资源,那么应该专门编写一个方法来释放此种资源。这样的类要和其他使用者约定:用完资源后必须调用close方法。
- 执行异步任务的方法不应该在dealloc里调用;只能在正常状态下执行的那些方法也不应该在dealloc里调用,因为此时对象已处于正在回收的状态了。
32. 编写“异常安全代码”时,留意内存管理问题
Objective-C的错误模型表明,异常只应发生严重错误后抛出,虽说如此,不过有时仍然需要编写代码来捕获并处理异常。比如使用Objective-C++来编码时,或是编码中用到了第三方程序库而此程序库所判处的异常又不受你控制时,就需要捕获及处理异常了。
在try块中,如果先保留了某个对象,然后在释放它之前又抛出了异常,那么,除非catch块能处理此问题,否则对象所占内存就将泄露。
异常处理例程将自动销毁对象,然而在手动管理引用计数时,销毁工作有些麻烦。以下面这段代码使用手工引用计数的Objective-C代码为例:
1 | @try { |
如果doSomethingThatMayThrow抛出异常,由于异常会令执行过程终止并跳转至catch块,因而其后的那行release代码不会运行。在这种情况下,如果代码抛出异常,那么对象就泄露了。解决办法是使用@finally块,无论是否抛出异常,其中的代码都保证会运行,且只运行一次。代码可改写如下:
1 | EOCSomeClass *object; |
由于@finally块也要引用object对象,所以必须把它从@try块里移到外面去。要是所有对象都得如此释放,那这样做就会非常乏味。而且@try块中的逻辑更为复杂,含有多条语句,那么很容易就会因为忘记某个对象而导致泄露。若泄露的对象是文件描述符或数据库连接等稀缺资源(或是这些稀缺资源的管理者),则可能引发大问题,因为这样导致应用程序把所有系统资源都抓在自己手里而不及时释放。
在ARC环境下,问题会更严重。下面这段使用ARC的代码与修改前的那段代码等效:1
2
3
4
5
6@try {
EOCSomeClass *object = [[EOCSomeClass alloc]init];
[object doSomethingThatMayThrow];
} @catch (NSException *exception) {
NSLog(@"Whoopse,there was an error.Oh well...");
}
现在问题更大了:由于不能调用release,所以无法像手动管理引用计数那样把释放操作移到@finally块中。你可能认为这种状况ARC自然会处理的。但实际上ARC不会自动处理,因为这样做需要加入大量样板代码,以便跟踪待清理的对象,从而在抛出异常时将其释放。可是,这段代码会严重影响运行期的性能,即便在不抛异常时也如此。而且,添加进来的额外代码还会明显增加应用程序的大小。这些副作用都不甚理想。
虽说默认状况下未开启,但ARC依然能生成这种安全处理异常所用的附加代码。-fobjc-arc-exception这个编译器标志用来开启此功能。其默认不开启的原因是:Objective-C代码中,只有当应用程序必须因异常状况而终止时才抛出异常。因此,如果应用程序即将终止,那么是否还会发生内存泄露就已经无关紧要了。在应用程序必须立即终止的情况下,还去添加安全处理异常所用的附加代码是没有意义的。
有种情况编译器会自动把-fobjc-arc-exception标志打开,就是处于Objective-C++模式时。因为C++处理异常所用的代码与ARC实现的附加代码类似,所以令ARC加入自己的代码以安全处理异常,其性能损失并不太大。此外,由于C++频繁使用异常,所以Objective-C++程序员很可能也会使用异常。
如果手工管理引用计数,而且必须捕获异常,那么要设法保证所编代码能把对象正确清理干净。若使用ARC且必须捕获异常,则需打开编译器的-fobjc-arc-exception标志。但最重要的是:在发现大量异常捕获操作时,应考虑重构代码,用NSError式错误信息传递法来取代异常。
- 要点:
- 捕获异常时,一定要注意将try块内所创立的对象清理干净。
- 在默认情况下,ARC不生成安全处理异常所需的清理代码。开启编译器标志后,可以生成这种代码,不过会导致应用程序变大,而且会降低运行效率。
33. 以引用避免保留环
@class EOCClassA;
@class EOCClassB;
@interface EOCClassA : NSObject
@property(nonatomic,strong)EOCClassB *other;
@end
@interface EOCClassB : NSObject
@property(nonatomic,strong)EOCClassA *other;
@end
避免循环引用的最佳方式就是弱引用。这种引用经常用来表示“非拥有关系”。将属性声明为unsafe_unretained即可。修改刚才那段代码,将其属性声明如下:
@class EOCClassA;
@class EOCClassB;
@interface EOCClassA : NSObject
@property(nonatomic,strong)EOCClassB *other;
@end
@interface EOCClassB : NSObject
@property(nonatomic,unsafe_unretained)EOCClassA *other;
修改之后,EOCClassB实例就不再通过other属性来拥有EOCClassA实例了。属性特质中的unsafe_unretained一词表明,属性值可能不安全,而且不归此实例所拥有。如果系统已经把属性所指的那个对象回收了,那么在其上调用方法可能会使应用程序崩溃。由于本对象并不保留属性对象,因此其有可能为系统所回收。
用unsafe_unretained修饰的属性特质,其语义同assign特质等价,然而assign通常只用于数值类型,unsafe_unretained则多用于对象类型。这个词本身就表明其所修饰的属性可能无法安全使用。
Objective-C中还有一项与ARC相伴的运行期特性,可能令开发者安全使用弱引用:这就是weak属性特质,它与unsafe_unretained的作用完全相同。然而,只要系统把属性回收,属性值就会自动设置为nil。在刚才那段代码中,EOCClassB的other属性可修改如下:
1 | @property(nonatomic,weak)EOCClassA *other; |
当指向EOCClassA实例的引用移除后,unsafe_unretained属性仍然指向那个已经回收的实例,而weak属性则指向nil。
使用weak属性而非unsafe_unretained引用可以令代码更安全。应用程序也许会显示出错误的数据,但不直接崩溃。
一般来说,如果不拥有某对象,那就不要保留它。这条规则对collection例外。collection虽然并不直接拥有其内容,但是它要代表自己所属的那个对象来保留这些元素。有时,对象中的引用会指向另外一个并不归自己所拥有的对象,比如Delegate模式就是这样
- 要点:
- 将某些引用设为weak,可避免出现“循环引用”。
- weak引用可以自动清空,也可以不自动清空。自动清空是随着ARC而引入的新特性,由运行期系统来实现。在具备自动清空功能的弱引用上,可以随意读写其数据,因为这种引用不会指向已经回收过的对象。
34. 以“自动释放池块”降低内存峰值
Objective-C对象的生命期取决于其引用计数。在Objective-C的引用计数架构中,有一项特性叫做“自动释放池”(autorelease pool)。释放对象有两种方式:一种是调用release方法,使其保留计数立即递减;另一种是调用autorelease方法,将其加入“自动释放池”中。自动释放池用于存放那些需要在稍后某个时刻释放的对象。清空自动释放池时,系统会向其中的对象发送release消息。
创建自动释放池所用语法如下:
1 | @autoreleasepool { |
一般情况下无须担心自动释放池的创建问题。Mac OS X与iOS应用程序分别运行于Cocoa及Cocoa Touch环境中。系统会自动创建一些线程,比方说主线程或是GCD机制中的线程,这些线程默认都有自动释放池,每次执行“事件循环“(event loop)时,就会将其清空。因此,不需要自己来创建”自动释放池块“。通常只有一个地方需要创建自动释放池块,那就是在mian函数里,我们用自动释放池来包裹应用程序的主入口点。比方说,iOS程序的main函数经常这样写:
1 | int main(int argc, char * argv[]) { |
从技术角度看,不是非得有个”自动释放池块”才行。因为块的末尾恰好就是应用程序的终止处,而此时操作系统会把程序所占的全部内存都释放掉。虽说如此,但是如果不写这个块的话,那么由UIApplicationMain函数所自动释放的那些对象,就没有自动释放池可以容纳了,于是系统会发出警告信息来表明这一情况。所以说,这个池可以理解成最外围捕捉全部自动释放对象所用的池。
位于自动释放池范围内的对象,将在此范围末尾处收到release消息。自动释放池可以嵌套。系统在自动释放对象时,会把它放到最内层的池里。比方说:
1 | @autoreleasepool { |
在本例中有两个对象,它们都由类的工厂方法所创建,这样创建出来的对象会自动释放。NSString对象放在外围的自动释放池中,而NSNumber对象则放在里层的自动释放池中。将自动释放池嵌套用的好处是,可以借此控制应用程序的内存峰值,使其不致过高。
考虑下面这段代码:
1 | for(int i=0;i<100000;i++){ |
如果“doSomethingWithInt:“方法要创建临时对象,那么这些对象很可能会放在自动释放池里。比方说,它们可能是一些临时字符串。但是,即便这些对象在调用完方法之后就不再使用了,它们也依然处于存活状态,因为目前还在自动释放池里,等待系统稍后将其释放并回收。然而,自动释放池要等线程执行下一次事件循环时才会清空。这就意味着在执行for循环时,会持续有新对象创建出来,并加入自动释放池中。所有这种对象都要等for循环执行完才会释放。这样一来,在执行for循环时,应用程序所占内存就会持续上涨,而等到所有临时对象都释放后,内存用量又会突然下降。
这种情况不甚理想,尤其当循环长度无法预知,必须取决于用户输入时更是如此。比方说,要从数据库中读取许多对象。代码可能会这么写:
1 | NSArray *databaseRecords = /*...*/; |
EOCPerson的初始化函数也许会像上例那样,再创建出一些临时对象。若记录有很多条,则内存中也会有很多不必要的临时对象,它们本来应该提早回收的。增加一个自动释放池即可解决此问题。如果把循环内的代码包裹在"自动释放池块"中,那么在循环中自动释放的对象就会放在这个池,而不是线程的主池里面。例如:
1 | NSArray *databaseRecords = /*...*/; |
加上这个自动释放池之后,应用程序在执行循环时的内存峰值就会降低,不再像原来那么高了。内存峰值是指应用程序在某个特定时段内的最大内存用量。新增的自动释放池块可以减少这个峰值,因为系统会在块的末尾把某些对象回收掉。而刚才提到的那种临时对象,就在回收之列。
自动释放池机制就像”栈“一样。系统创建好自动释放池之后,就将其推入栈中,而清空自动释放池,则相当于将其从栈中弹出。在对象上执行自动释放操作,就等于将其放入栈顶的那个池里。
是否应该用池来优化效率,完全取决于具体的应用程序。首先得监控内存用量,判断其中有没有需要解决的问题,如果没完成这一步,那就别急着优化。尽管自动释放池块的开销不太大,但毕竟还是有的,所以尽量不要建立额外的自动释放池。
如果在ARC出现之前就写过Objective-C程序,那么可能还记得有种老式写法,就是使用NSAutoreleasePool对象。这个特殊的对象与普通对象不同,它专门用来表示自动释放池。就像新语法中的自动释放池块一样。但是这种写法并不会在每次执行for循环时都清空池,此对象更为“重量级”,通常用来创建那种偶尔需要清空的池,比方说:
1 | NSArray *databaseRecords = /*...*/; |
现在不需要再这样写代码了。采用随着ARC所引入的新语法,可以创建出更为”轻量级“的自动释放池。原来缩写的代码可能会每执行n次循环清空一次自动释放池,现在可以改用自动释放池块把for循环中的语句包起来,这样的话,每次执行循环时都会简历并清空自动释放池。
@autoreleasepool语法还有个好处:每个自动释放池均有其范围,可以避免无意间误用了那些在清空池后已为系统所回收的对象。比方说,考虑下面这段采用旧式写法的代码:
1 | NSAutoreleasePool *pool = [[NSAutoreleasePool alloc]init]; |
调用”userObject:“方法时所传入的那个对象,可能已经为系统所回收了。同样的代码改用信使写法就变成了:1
2
3
4@autoreleasepool {
id object = [self createObject];
}
[self useObject:object];
这次根本就无法编译,因为object变量出了自动释放池块的外围就不可用了,所以在调用”useObject:“方法时不能用它做参数。
- 要点:
- 自动释放池排布在栈中,对象收到autorelease消息后,系统将其放入到最顶端的池里。
- 合理运用自动释放池,可降低应用程序的内存峰值。
- @autoreleasepool这种新式写法能创建出更为轻便的自动释放池。
35. 用“僵尸对象”调试内存管理问题
向已回收的对象发送消息是不安全的。这么做有时可以,有时不行。具体可行与否,完全取决于对象所占内存有没有为其他内容所覆写。而这块内存有没有移作他用,又无法确定,因此,应用程序只是偶尔崩溃。在没有崩溃的情况下,那块内存可能只复用了其中一部分,所以对象中的某些二进制数据依然有效。还有一种可能,就是那块内存恰好为另外一个有效且存活的对象所占据。在这种情况下,运行期系统会把消息发到新对象那里,而此对象也许能应答,也许不能。
Cocoa提供了“僵尸对象”(Zombie Object)这个非常方便的功能。启用这项调试功能之后,运行期系统会把所有已经回收的实例转化成特殊的“僵尸对象”,而不会真正回收它们。这种对象所在的核心内存无法重用,因此不可能遭到覆写。僵尸对象收到消息后,会抛出异常,其中准确说明了发送过来的消息,并描述了回收之前的那个对象。僵尸对象是调试内存管理问题的最佳方式。
将NSZombieEnabled环境变量设为YES,即可开启此功能。在Mac OS X系统中用bash运行应用程序时,可以这么做:1
2export NSZombieEnabled=“YES”
./app
给僵尸对象发送消息后,控制台会打印消息,而应用程序则会终止。打印出来的消息就像这样:1
*** -[CFString respondsToSelector:]:message sent to deallocated instance 0x7ff9e9c080e0
在Xcode中开启方法为:编辑应用程序的Scheme,在对话框左侧选择”Run“,然后切换至”Diagnostics“分页,最后勾选”Enable Zombie Objects“选项。
僵尸对象的工作原理是什么呢?它的实现代码深植与Objective-C的运行期程序库、Foundation框架及CoreFoundation框架中。系统在即将回收对象时,如果发现通过环境变量启用了僵尸对象功能,那么还将执行一个附加步骤。这一步就是把对象转化为僵尸对象,而不彻底回收。
下面代码有助于理解这一步所执行的操作:
#import <Foundation/Foundation.h>
#import <objc/runtime.h>
@interface EOCClass : NSObject
@end
#import "EOCClass.h"
@implementation EOCClass
@end
void PrintClassInfo(id obj){
Class cls = object_getClass(obj);
Class superCls = class_getSuperclass(cls);
NSLog(@"=== %s : %s ===",class_getName(cls),class_getName(superCls));
}
int main(int argc, char *argv[]){
EOCClass *obj = [[EOCClass alloc]init];
NSLog(@"Before release:");
PrintClassInfo(obj);
[obj release];
NSLog(@"After release:");
PrintClassInfo(obj);
}
本例代码中有个函数,可以根据给定的对象打印出所属的类及其超类名称。此函数没有直接给对象发送Objective-C的class消息,而是调用了运行期库里的object_getClass()函数。因为如果参数已经是僵尸对象了,那么给其发送Objective-C消息后,控制台会打印错误消息,而且应用程序会崩溃。本例代码将输出下面这种消息:1
2
3
4Before release:
=== EOCClass : NSObject ===
After release:
=== _NSZombie_EOCClass : nil ====
对象所属的类已由EOCClass变成_NSZombie_EOCClass。_NSZombie_EOCClass实际上是在运行期生成的,当首次碰到EOCClass类的对象要变成僵尸对象时,就会创建这么一个类。创建过程中用到了运行期程序库里的函数,它们的功能很强大,可以操作类列表。
僵尸类是从名为NSZombie的模板类里复制出来的。这些僵尸类没有多少事情可做,只是充当一个标记。接下类介绍它们是怎样充当标记的。首先来看下嘛这段伪代码,其中演示了系统如何根据需要创建出僵尸类,而僵尸类又如何把待回收的对象转化成僵尸对象。
//Obtain the class of the object being deallocated
Class cls = object_getClass(slef);
//Get the class's name
const char *clsName = class_getName(cls);
//Prepend _NSZombie_ to the class name
const char *zombieClsName = "_NSZombie_" + clsName;
//See if the specific zombie class exists
Class zombieCls = objc_lookUpClass(zombieClsName);
//If the specific zombie class doesn't exist
//then it needs to be created
if(!zombieCls){
//Obtain the template zombie class called _NSZombie_
Class baseZombieCls = objc_lookUpClass("_NSZombie_");
//Duplicate the base zombie class,where the new class's
//name is the prepended string from above
zombieCls = objc_duplicateClass(baseZombieCls, zombieClsName, 0);
}
//Perform normal destruction of the object being deallocated
objc_destructInstance(self);
//Set the class of the object being deallocated
//to the zombie class
objc_setClass(self,zombieCls);
//The class of 'self' is now _NSZombie_OrignalClass
这个过程其实就是NSObject的dealloc方法所做的事。运行期系统如果发现NSZombieEnabled环境变量已设置,那么就把dealloc方法”调配“(swizzle)成一个会执行上述代码的版本。执行到程序末尾时,对象所属的类已经变为_NSZombie_OriginalClass了,其中OriginalClass指的是原类名。
代码中的关键之处在于:对象所占内存没有(通过调用free()方法)释放,因此,这块内存不可复用。虽说内存泄露了,但这只是个调试手段,制作正式发行的应用程序时不会把这项功能打开,所以这种泄露问题无关紧要。
但是,系统为何要给每个变为僵尸的类都创建一个对应的新类呢?这是因为,给僵尸对象发消息后,系统可由此知道该对象原来所属的类。假如把所有僵尸对象都归到NSZombie类里,那原来的类名就丢了。创建新类的工作由运行期函数objc_duplicateClass()来完成,它会把整个NSZombie类结构拷贝一份,并赋予其新的名字。副本类的超类、实例变量及方法都和复制前相同。还有种做法也能保留旧类名,那就是不拷贝NSZombie,而是创建继承自NSZombie的新类,但是用相应的函数完成此功能,其效率不如直接拷贝高。
僵尸类的作用会在消息转发例程(第12条)中体现出来。NSZombie类(以及所有从该类拷贝出来的类)并未实现任何方法。此类没有超类,因此和NSObject一样,也是个”根类“,该类只有一个实例变量,叫做isa,所有Objective-C的根类都必须有此变量。由于这个轻量级的类没有实现任何方法,所以发给它的全部消息都要经过”完整的消息转发机制“。
在完整的消息转发机制中,forwarding是核心,调试程序时,大家可能在栈回溯消息里看见过这个函数。它首先要做的事情就包含检查接收消息的对象所属的类名。若名称前缀为NSZombie,则表明消息接收者是僵尸对象,需要特殊处理。此时会打印一条消息,其中指明了僵尸对象所收到的消息及原来所属的类,然后应用程序就终止了。在僵尸类名中嵌入原来类名的好处,这时就可以看出来了。只要把NSZombie从僵尸类名的开头拿掉,剩下的就是原始类名。下面伪代码演示了这一过程:
//Obtain the class of the object being deallocated
Class cls = object_getClass(slef);
//Get the class's name
const char *clsName = class_getName(cls);
//Check if the class is prefixed with _NSZombie_
if(string_has_prefix(clsName,"_NSZombie_"){
//If so ,this object is a zombie
//Get the original class name by skipping past the
//_NSZombie_,i.e taking the substring from character 10
const char *originalClsName = substring_from(clsName,10);
//Get the selector name of the message
const char *selectorName = sel_getName(_cmd);
//Log a message to indicate wich selector is
//being sent to which zombie
Log("*** -[%s %s]:message sent to deallocated instance %p",originalClsName,selectorName,self);
//Kill the application
abort();
}
- 要点:
- 系统在回收对象时,可以不将其真的回收,而是把它转化成为僵尸对象。通过环境变量NSZombieEnabled可开启此功能。
- 系统会修改对象的isa指针,令其指向特殊的僵尸类,从而使该对象变成僵尸对象。僵尸类能够响应所有的选择子,响应方式为:打印一条包含消息内容及其接收者的消息,然后终止应用程序。
36. 不要使用retainCount
NSObject协议中定义了下列方法,用于查询对象当前的保留计数:1
- (NSUInteger)retainCount
这个方法看上去似乎挺合理、挺有用的。它毕竟返回了保留计数,而此值对每个对象来说显然都很重要。但问题在于,保留计数的绝对数值一般都与开发者所应留意的事情完全无关。即便只在调试时才调用此方法,通常也还是无所助益的。
此方法之所以无用,其首要原因在于:它所返回的保留计数只是某个给定时间点上的值。该方法并未考虑到系统会稍后把自动释放池清空,因而不会将后续的释放操作从返回值里减去,这样的话,此值就未必能真实反映实际的保留计数了。因此,下面这种写法非常糟糕:1
2
3while([object retainCount]){
[object release];
}
这种写法的第一个错误是:它没考虑到后续的自动释放操作,只是不停地通过释放操作来降低保留计数,直至对象为系统所回收。假如此对象也在自动释放池里,那么稍后系统清空池子时还要把它再释放一次,而这将导致程序崩溃。
第二个错误在于:retainCount可能永远不返回0,因为有时系统会优化对象的释放行为,在保留计数还是1的时候就把它回收了。只有在系统不打算这么优化时,计数值才会递减至0。因此,保留计数可能永远都不会完全归零。所以说,这段代码就算有时能正常运行,也多半是凭运气,而非理性判断。对象回收之后,如果while循环仍然在运行,那么目前的运行期系统一般会直接令应用程序崩溃。
从来都不需要编写这种代码。这段代码所要实现的操作,应该通过内存管理来解决。开发者在期望系统于某处回收对象时,应该确保没有尚未抵消的保留操作,也就是不要令保留计数大于期望值。在这种情况下,如果发现某对象的内存泄露了,那么应该检查还有谁仍然保留这个对象,并查明为何没有释放此对象。
下面这段代码:
NSString *string = @"Some string";
NSLog(@"string retainCount = %lu",[string retainCount]);
NSNumber *numberI = @1;
NSLog(@"numberI retainCount = %lu",[numberI retainCount]);
NSNumber *numberF = @3.141f;
NSLog(@"numberF retainCount = %lu",[numberF retainCount]);
在64位Mac OS X系统中,用Clang4.1编译后,这段代码输出的消息如下:
string retainCount = 18446744073709551615
numberI retainCount = 9223372036854775807
numberF retainCount = 1
第一个对象的保留计数是264-1,第二个对象的保留计数是263-1。由于二者皆为“单例对象”,所以其保留计数都很大。系统会尽可能把NSString实现成单例对象。如果字符串像本例所举的这样,是个编译器常量,那么就可以这样来实现了。在这种情况下,编译器会把NSString对象所表示的数据放到应用程序的二进制文件里,这样的话,运行程序时就可以直接用了,无须再创建NSString对象。NSNumber也类似,它使用了一种叫做“标签指针”(tagged pointer)的概念来标注特定类型的数值。这种做法不使用NSNumber对象,而是把与数值有关的全部消息都放在指针值里面。运行期系统会在消息派发期检测到这种标签指针,并对它执行相应操作,使其行为看上去和真正的NSNumber对象一样。这种优化只在某些场合使用,比如范例中的浮点数对象就没有优化,所以其保留计数就是1。
另外,像刚才所说的那种单例对象,其保留计数绝对不会变。这种对象的保留及释放操作都是“空操作”。可以看到,即便两个单例对象之间,其保留计数也各不相同,系统对其保留计数的这种处理方式再一次表明:我们不应该总是依赖保留计数的具体值来编码。
- 要点:
- 对象的引用计数看似有用,实则不然,因为任何给定的时间点上的“绝对引用计数”都无法反映对象生命期的全貌。
- 引入ARC之后,retainCount方法就正式废止了,在ARC下调用该方法会导致编译器报错。
———————————————————————————
六、块与大中枢派发
37. 理解“块”这一概念
块的基础知识
块与函数类似,只不过是直接定义在另一个函数里的,和定义它的那个函数共享同一个范围内的东西。块用“^”符号来表示,后面跟着一对花括号,括号里面是块的实现代码。例如:1
2
3^{
//Block implementation here
}
块其实就是个值,而且自有其相关类型。与int、float或Objective-C对象一样,也可以把块赋给变量,然后像使用其他变量那样使用它。块类型的语法与函数指针近似。下面列出的这个块很简单,没有参数,也没有返回值,定义了一个名为someBlock的变量:1
2
3void (^someBlock)() = ^{
//Block implementation here
};
- 块类型的语法结构如下:
1
return_type (^block_name)(parameters)
下面这种写法所定义的块,返回int值,并且接受两个int做参数:1
2
3int(^addBlock)(int a,int b) = ^(int a,int b){
return a + b;
};
块的强大之处是:在声明它的范围里,所有变量都可以为其所捕获。这也就是说,那个范围里的全部变量,在块里依然可用。比如,下面这段代码所定义的块,就使用了块以外的变量:
1
2
3
4
5int addtional = 5;
int(^addBlock)(int a,int b) = ^(int a,int b){
return a + b + addtional;
};
int add = addBlock(2,5);///< add = 12默认情况下,为块所捕获的变量,是不可以在块里修改的。在本例中,假如块内的代码改动了additional变量的值,那么编译器就会报错。不过,声明变量的时候可以加上__block修饰符,这样就可以在块内修改了。例如,可以用下面这个块来枚举数组中的元素(参见第48条),以判断其中有多少个小于2的数:
1
2
3
4
5
6
7
8
9NSArray *array = @[@0,@1,@2,@3,@4,@5];
__block NSInteger count = 0;
[array enumerateObjectsUsingBlock:
^(NSNumber *number, NSUInteger idx, BOOL * _Nonnull stop) {
if([number compare:@2]==NSOrderedAscending){
count++;
}
}];
//count = 2
这段范例代码也演示了“内联块”(inline block)的用法。传给”enumerateObjectsUsingBlock:”方法的块并未先赋给局部变量,而是直接内联在函数调用里了。由这种常见的编码习惯也可以看出块为何如此有用。在Objective-C语言引入块的这一特性之前,想要编出与刚才那段代码相同的功能,就必须传入函数指针或选择子的名称,以供枚举方法调用。状态必须手工传入传出,这一版通过“不透明的void指针“实现,如此一来,就得再写几行代码了,而且还会令方法变得有些松散。与之相反,若声明内联形式的块,则可把所有业务逻辑都放在一处。
如果块所捕获的变量是对象类型,那么就会自动保留它。系统在释放这个块的时候,也会将其一并释放。这就引出了一个与块有关的重要问题。块本身可视为对象。实际上,在其他Objective-C对象所能响应的选择子中,有很多是块也可以响应的。而最重要之处则在于,块本身也和其他对象一样,有引用计数。当最后一个指向块的引用移走之后,块就回收了。回收时也会释放块所捕获的变量,以便平衡捕获时所执行的保留操作。
如果将块定义在Objective-C类的实例方法中,那么除了可以访问类的所有实例变量之外,还可以使用self变量。块总能修改实例变量,所以在声明时无须加block。不过,如果通过读取或写入操作捕获了实例变量,那么也会自动把self变量一并捕获了,因为实例变量是与self所指代的实例关联在一起的。例如,下面这个块声明在EOCClass类的方法中:
#import "EOCClass.h"
@implementation EOCClass
-(void)anInstanceMethod{
void (^someBlock)() = ^{
_anInstanceVariable = @"Something";
NSLog(@"_anInstanceVariable = %@",_anInstanceVariable);
};
}
@end
如果某个EOCClass实例正在执行anInstanceMethod方法,那么self变量就指向此实例。由于块里没有明确使用self变量,所以很容易就会忘记self变量其实也是为块所捕获了。直接访问实例变量和通过self来访问时等效的:1
self-> _anInstanceVariable = @"Something";
之所以要捕获self变量,原因正在于此。我们经常通过属性访问实例变量,在这种情况下,就要指明self了:1
self.aProperty = @“Something”;
然而,一定要记住:self也是个对象,因而块在捕获它时也会将其保留。如果self所指代的那个对象同时也保留了块,那么这种情况通常就会导致“循环引用”。
块的内部结构
每个Objective-C对象都占据着某个内存区域。因为实例变量的个数及对象所包含的关联数据互不相同,所以每个对象所占的内存区域也有大有小。块本身也是对象,在存放块对象的内存区域中,首个变量是指向Class对象的指针,该指针叫做isa。其余内存里含有块对象正常运转所需的各种信息。下图详细描述了块对象的内存布局:
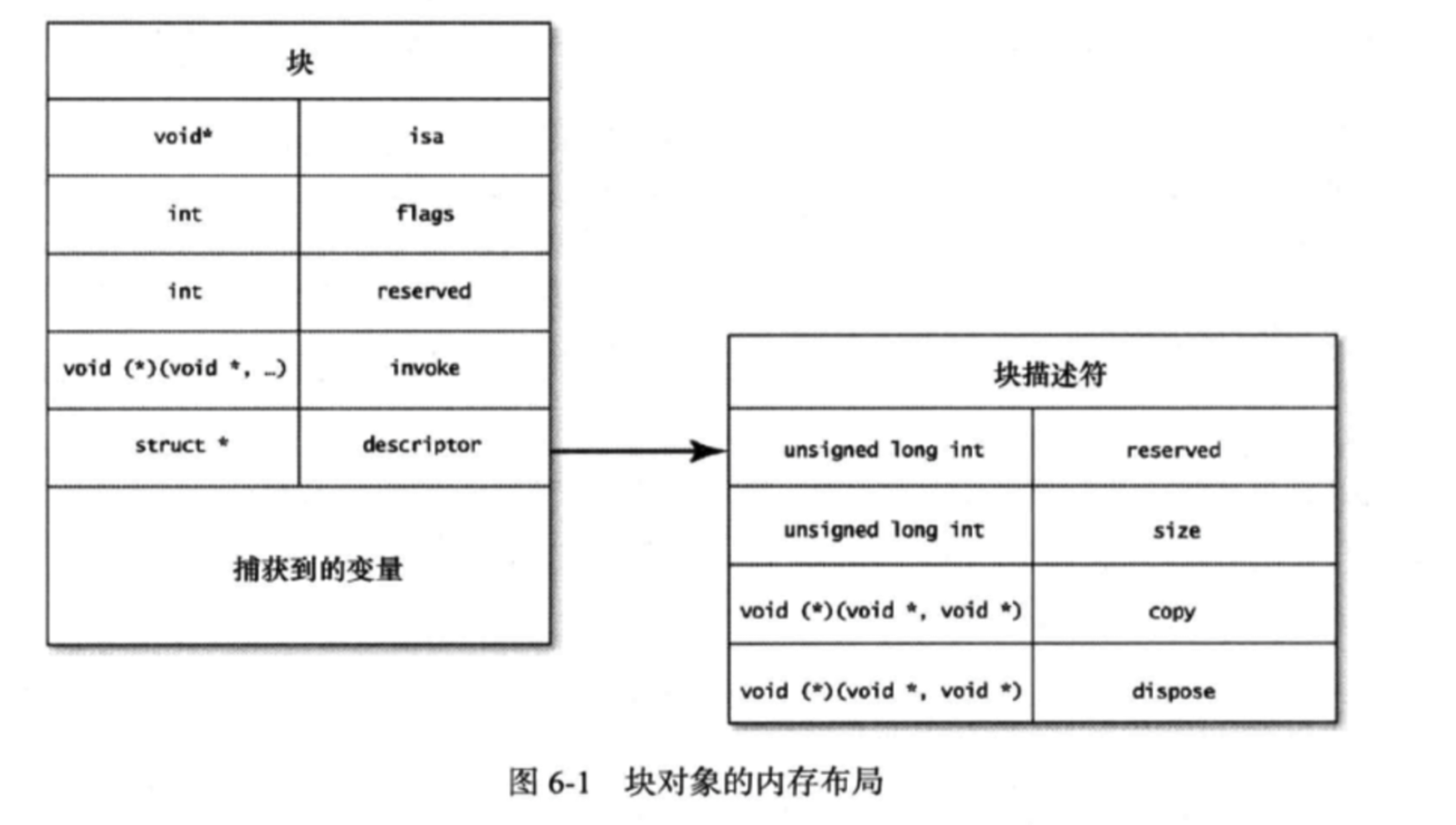
在内存布局中,最重要的就是invoke变量,这是个函数指针,指向块的实现代码。函数原型至少要接受一个void*型的参数,此参数代表块。刚才说过,块其实就是一种代替函数指针的语法结构,原来使用函数指针时,需要用”不透明的void指针“来传递状态。而改用块之后,则可以把原来用标准C语言特性所编写的代码封装成简明且易用的接口。
descriptor变量是指向结构体的指针,每个块里都包含此结构体,其中声明了块对象的总体大小,还声明了copy与dispose这两个辅助函数所对应的函数指针。辅助函数在拷贝及丢弃块对象时运行,其中会执行一些操作,比方说,前者要保留捕获的对象,而后者则将之释放。
块还会把它所捕获的所有变量都拷贝一份。这些拷贝放在descriptor变量后面,捕获了多少个变量,就要占据多少内存空间。请注意,拷贝的并不是对象本身,而是指向这些对象的指针变量。invoke函数需要把块对象作为参数传进来是因为在执行块时,要从内存中把这些捕获到的变量读出来。
全局块、栈块及堆块
定义块的时候,其所占的内存区域是分配在栈中的。这就是说,块只在定义它的那个范围内有效。例如,下面这段代码就有危险:1
2
3
4
5
6
7
8
9
10
11void (^block)();
if(/*some condition*/){
block = ^{
NSLog(@"Block A");
};
}else{
block = ^{
NSLog(@"Block B");
};
}
block();
定义在if及else语句中的两个块都分配在栈内存中。编译器会给每个块分配好栈内存,然而等离开了相应的范围之后,编译器有可能把分配给块的内存覆写掉。于是,这两个块只能保证在对应的if或else语句范围内有效。这样写出来的代码可以编译,但是运行起来时而正确,时而错误。若编译器未覆写待执行的块,则程序照常运行,若覆写,则程序崩溃。
为解决此问题,可给块对象发送copy消息以拷贝之。这样的话,就可以把块从栈复制到堆了。拷贝后的块,可以在定义它的那个范围之外使用。而且,一旦复制到堆中,块就成了带引用计数的对象了。后续的复制操作都不会真的执行复制,只是递增块对象的引用计数。如果不再使用这个块,那就应该将其释放,在ARC下会自动释放,而手动管理引用计数时则需要自己来调用release方法。当引用计数降为0时,”分配在堆上的块“会像其他对象一样,为系统所回收。而”分配在栈上的块“则无须明确释放,因为栈内存本来就会自动回收。
我们只需给代码加上两个copy方法调用,就可令其变得安全了:1
2
3
4
5
6
7
8
9
10
11void (^block)();
if(/*some condition*/){
block = [^{
NSLog(@"Block A");
}copy];
}else{
block = [^{
NSLog(@"Block B");
}copy];
}
block();
现在代码就安全了。如果手动管理引用计数,那么在用完块之后还需将其释放。
除了“栈块”和“堆块”之外,还有一类块叫做“全局块”。这种块不会捕获任何状态(比如外围的变量等),运行时也无须有状态来参与。块所使用的整个内存区域,在编译期已经完全确定了,因此,全局块可以声明在全局内存里,而不需要在每次用到的时候于栈中创建。另外,全局块的拷贝操作是个空操作,因为全局块决不可能为系统所回收。这种块实际上相当于单例。下面就是个全局块:1
2
3void (^block)() = ^{
NSLog(@"This is a block");
};
由于运行该块所需的全部信息都能在编译期确定,所以可把它做成全局块。这完全是种优化技术:若把如此简单的块当成复杂的块来处理,那就会在复制及丢弃该块时执行一些无谓的操作。
- 要点:
- 块是C、C++、Objective-C中的词法闭包。
- 块可接受参数,也可返回值。
- 块可以分配在栈或堆上,也可以是全局的。分配在栈上的块可拷贝到堆里,这样的话,就和标准的Objective-C对象一样,具备引用计数了。
38. 为常用的块类型创建typedef
块类型的语法结构如下:1
return_type (^block_name)(parameters)
与其他类型的变量不同,在定义块变量时,要把变量名放在类型之中,而不要放在右侧。这种语法非常难记,也非常难读。鉴于此,我们应该为常用的块类型起个别名,尤其是打算把代码发不成API供他人使用时,更应这样做。开发者可以起个更为易读的名字来表示块的用途,而把块的类型隐藏在其后面。为了隐藏复杂的块类型,需要用到C语言中名为“类型定义”的特性。typedef关键字用于给类型起个易读的别名。比方说,想定义新类型,用以表示接受BOOL及int参数并返回int值的块,可通过下列语句来做:1
typedef int(^EOCSomeBlock)(BOOL flag,int value);
此后,不用再以复杂的块类型来创建变量了,直接使用新类型即可:1
2
3EOCSomeBlock block = ^(BOOL flag,int value){
//Implementation
};
这次代码读起来就顺畅多了:与定义其他变量时一样,变量类型在左边,变量名在右边。
通过这项特性,可以把使用块的API做得更为易用些。类里面有些方法可能需要用块来做参数,比如执行异步任务时所用的“completion handler”参数就是块,凡遇到这种情况,都可以通过定义别名使代码变得更为易读。比方说,类里有个方法可以启动任务,它接受一个块作为处理程序,在完成任务之后执行这个块。若不定义别名,则方法签名会像下面这样:1
2-(void)startWithCompletionHandler:
(void(^)(NSData *data,NSError *error))completion;
注意,定义方法参数所用的块类型语法,又和定义变量时不同。若能把方法签名中的参数类型写成一个词,那读起来就顺口多了。于是,可以给参数类型起个别名,然后使用此名称来定义:1
2typedef void(^EOCCompletionHandler)(NSData *data,NSError *error);
-(void)startWithCompletionHandler:(EOCCompletionHandler)completion;
现在参数看上去就简单多了,而且易于理解。
使用类型定义还有个好处,就是当你打算重构块的类型签名时会很方便。比方说,要给原来的completion handler块再加一个参数,用以表示完成任务所花的时间,那么只需修改类型定义语句即可:1
typedef void(^EOCCompletionHandler)(NSData *data,NSTimeInterval duration,NSError *error);
修改之后,凡是使用了这个类型定义的地方,比如方法签名等处,都会无法编译,而且报的是同一种错误,于是开发者可据此逐个修复。若不用类型定义,而直接写块类型,那么代码中要修改的地方就更多了。开发者很容易忘掉其中一两处,从而引发难于排查的bug。
最好在使用块类型的类中定义这些typedef,而且还应该把这个类的名字加在由typedef所定义的新类型名前面,这样可以阐明块的用途。还可以用typedef给同一个块签名类型创建数个别名。在这件事上,多多益善。
Mac OS X与iOS的Accounts框架就是个例子。在该框架中可以找到下面这两个类型定义语句:1
2typedef void(^ACAccountStoreSaveCompletionHandler)(BOOL success, NSError *error);
typedef void(^ACAccountStoreRequestAccessCompletionHandler)(BOOL granted, NSError *error);
这两个类型定义的签名相同,但用在不同的地方。开发者看到类型别名及签名中的参数之后,很容易就能理解此类型的用途。它们本来也可以合并成一个typedef,比如叫做ACAccountStorBooleanCompletionHandler,使用那两个别名的地方,都可以统一使用此名称。然后,这么做之后,块与参数的用途看上去就不那么明显了。
与此相似,如果有好几个类都要执行相似但各有区别的异步任务,而这几个类又不能放入同一个继承体系,那么,每个类就应该有自己的completion handler类型。这几个completion handler的前面也许完全相同,但最好还是在每个类里都各自定义一个别名,而不要共用同一个名称。反之,若这些类能纳入同一个继承中,则应该将类型定义语句放在超类中,以供各子类使用。
- 要点:
- 以typedef重新定义块类型,可令块变量用起来更加简单。
- 定义新类型时应遵从现有的命名规范,勿使其名称与别的类型相冲突。
- 不妨为同一个块签名定义多个类型别名。如果要重构的代码使用了块类型的某个别名,那么只需修改相应的typedef中的块签名即可,无须改动其他typedef。
39. 用handler块降低代码分散程度
与使用委托模式的代码相比,用块写出来的代码显得更为简洁。异步任务执行完毕后所需运行的业务逻辑,和启动异步任务所用的代码放在了一起。而且,由于块声明在创建获取器的范围内,所以它可以访问此范围内的全部变量。
委托模式有个缺点:如果类要分别使用多个获取器下载不同数据,那么就得在delegate回调方法里根据传入的获取器参数来切换。
把成功情况和失败情况放在同一个块中,缺点是:由于全部逻辑都写在一起,所以会令块变得比较长,切比较复杂。然而只用一个块的写法也有好处,那就是更为灵活。比方说,在传入错误信息时,可以把数据也传进来。有时数据正下载到一半,突然网络故障了。在这种情况下,可以把数据及相关的错误都传给块。这样的话,completion handler就能根据此判断问题并适当处理了,而且还可利用已下载好的这部分数据做些事情。还有个优点是:调用API的代码可能会在处理成功响应的过程中发现错误。这种情况需要和网络数据获取器所认定的失败情况按同一方式处理。此时,如果采用单一块的写法,那么就能把这种情况和获取器认定的失败情况统一处理了。要是把成功情况和失败情况交给两个不同的处理程序来负责,那么就没办法共享同一份错误处理代码了,除非把这段代码单独放在一个方法里,而这又违背了我们想把全部逻辑代码都放在一处的初衷。
建议使用同一个块来处理成功与失败情况。
基于handler来设计API还有个原因,就是某些代码必须运行在特定的线程上。比方说,Cocoa与Cocoa Touch中的UI操作必须在主线程上执行。这就相当于GCD中的“主队列”。因此,最好能由调用API的人来决定handler应该运行在哪个线程上。NSNotificationCenter就属于这种API,它提供了一个方法,调用者可以经由此方法来注册想要接收的通知,等到相关事件发生时,通知中心就会执行注册好的那个块。调用者可以指定某个块应该安排在哪个执行队列里,然而这不是必需的。若没有指定队列,则按默认方式执行,也就是说,将由投递通知的那个线程来执行。下列方法可用来新增观察者:1
2
3
4- (id <NSObject>)addObserverForName:(nullable NSString *)name
object:(nullable id)obj
queue:(nullable NSOperationQueue *)queue
usingBlock:(void (^)(NSNotification *note))block
此处传入的NSOperationQueue参数就表示触发通知时用来执行块代码的那个队列。这是个“操作队列”,而非“底层GCD队列”,不过两者语义相同。
- 要点:
- 要创建对象时,可以使用内联的handler块将相关业务逻辑一并声明。
- 在有多个实例需要监控时,如果采用委托模式,那么经常需要根据传入的对象来切换,而若改用handler块来实现,则可直接将块与相关对象放在一起。
- 设计API时如果用到了handler块,那么可以增加一个参数,使调用者可通过此参数来决定应该把块安排在哪个队列上执行。
40. 用块引用其所属对象时,不要出现保留环
使用块时,若不仔细思量,则很容易导致循环引用。比方说,下面这个类就提供了一套接口,调用者可由此从某个URL中下载数据。在启动获取器时,可设置completion handler,这个块会在下载结束之后以回调方式执行。为了能在p_requestCompleted方法执行调用者所指定的块,这段代码需要把completion handler保存到实例变量里面。
//EOCNetworkFetcher.h
typedef void(^EOCNetworkFetcherCompletionHandler)(NSData *data);
@interface EOCNetworkFetcher : NSObject
@property(nonatomic,strong,readonly)NSURL *url;
-(instancetype)initWithURL:(NSURL *)url;
-(void)startWithCompletionHandler:
(EOCNetworkFetcherCompletionHandler)completion;
@end
.
//EOCNetworkFetcher.m
@interface EOCNetworkFetcher ()
@property(nonatomic,strong,readwrite)NSURL *url;
@property(nonatomic,copy)EOCNetworkFetcherCompletionHandler completionHandler;
@property(nonatomic,strong)NSData *downloadedData;
@end
@implementation EOCNetworkFetcher
-(instancetype)initWithURL:(NSURL *)url{
if(self = [super init]){
_url = url;
}
return self;
}
-(void)startWithCompletionHandler:(EOCNetworkFetcherCompletionHandler)completion{
self.completionHandler = completion;
//Start the request
//Request sets downloadedData property
//When request is finished,p_requestCompleted is called
}
-(void)p_requestCompleted{
if(_completionHandler){
_completionHandler(_downloadedData);
}
}
@end
某个类可能会创建这种网络数据获取器对象,并用其从URL中下载数据:
#import "EOCClass.h"
#import "EOCNetworkFetcher.h"
@interface EOCClass ()
{
EOCNetworkFetcher *_networkFetcher;
NSData *_fetchedData;
}
@end
@implementation EOCClass
-(void)downloadData{
NSURL *url = [[NSURL alloc]initWithString:@"http://www.example.com/something.dat"];
_networkFetcher = [[EOCNetworkFetcher alloc]initWithURL:url];
[_networkFetcher startWithCompletionHandler:^(NSData *data) {
NSLog(@"Request URL %@ finished",_networkFetcher.url);
_fetchedData = data;
}];
}
@end
这里就造成了一个循环引用。因为completion handler块要设置_fetchedData实例变量,所以它必须捕获self变量(第37条)。这就是说,handler块保留了创建网络数据获取器的那个EOCClass实例。而EOCClass实例则通过strong实例变量保留了获取器,最后,获取器对象又保留了handler块。下图描述了这个环:
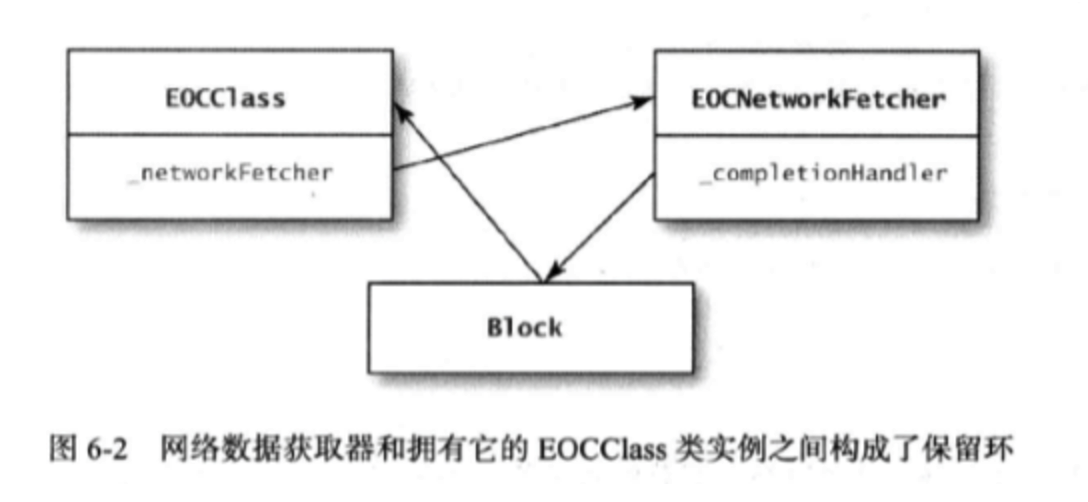
要打破循环引用也很容易:要么令_networkFetcher实例变量不要引用获取器,要么令获取器的completionHandler属性不再持有handler块。在网络数据获取器这个例子中,应该等completion handler块执行完毕后,再去打破引用环,以便使获取器对象在handler块执行期间保持存活状态。比方说,completion handler块的代码可以这么修改:1
2
3
4
5[_networkFetcher startWithCompletionHandler:^(NSData *data) {
NSLog(@"Request URL %@ finished",_networkFetcher.url);
_fetchedData = data;
_networkFetcher = nil;
}];
如果设计API时用到了completion handler这样的回调块,那么很容易形成循环引用,所以必须意识到这个重要问题。一般来说,只要适时清理掉环中的某个引用,即可解决此问题,然而,未必总有这种机会。在本例中,唯有completion handler运行过后,方能解除引用环。若是completion handler一直不运行,那么引用环就无法打破,于是内存就会泄露。
像completion handler块这种写法,还可能引入另外一种形式的引用环。如果completion handler块所引用的对象最终又引用了这个块本身,那么就会出现引用环。比方说,我们修改下这个例子,使调用API的那段代码无须在执行期间保留指向网络数据获取器的引用,而是设定一套机制,令获取器对象自己设法保持存活。要想保持存活,获取器对象可以在启动任务时把自己加到全局的collection中(比如用set来实现这个collection),待任务完成后,再移除。而调用方则需将其代码修改如下:1
2
3
4
5
6
7
8-(void)downloadData{
NSURL *url = [[NSURL alloc]initWithString:@"http://www.example.com/something.dat"];
EOCNetworkFetcher *networkFetcher = [[EOCNetworkFetcher alloc]initWithURL:url];
[networkFetcher startWithCompletionHandler:^(NSData *data) {
NSLog(@"Request URL %@ finished",_networkFetcher.url);
_fetchedData = data;
}];
}
大部分网络通信库都采用这种方法,因为假如令调用者自己来将获取器对象保持存活的话,他们会觉得麻烦。Twitter框架的TWRequest对象也用的这个办法。然后,本例这样做会引入引用环。completion handler块其实要通过获取器对象来引用其中的URL(引用了EOCNetworkFetcher的url属性)。于是,块就要保留获取器,而获取器反过来又经由其completion handler属性保留了这个块。所幸要修复这个问题也不难。回想一下,获取器对象之所以要把completion handler块保存在属性里面,其唯一目的就是想稍后使用这个块。于是,获取器一旦运行过completion handler之后,就没必要再保留它了。所以,只需将p_requestCompleted方法按照如下方式修改即可:1
2
3
4
5
6-(void)p_requestCompleted{
if(_completionHandler){
_completionHandler(_downloadedData);
}
self.completionHandler = nil;
}
这样一来,只要下载请求执行完毕,引用环就解除了,而获取器对象也将会在必要时为系统所回收。请注意,之所以要在start方法中把completion handler作为参数传进去,这也是一条重要原因。假如把completion handler暴露为获取器对象的公共属性,那么就不便在执行完下载请求之后直接将其清理掉了。因为既然已经把handler作为属性公布了,那就意味着调用者可以自由使用它,若是此时又在内部将其清理掉的话,则会破坏“封装语义”。在这种情况下要想打破引用环,只有一个办法可用,那就是强迫调用者在handler代码里自己把completionHandler属性清理干净。可这并不是十分合理,因为你无法假定调用者一定会这么做。
这两种引用环都很容易发生。使用块来编程时,一不小心就会出现这种bug,反过来说,只要小心谨慎,这种问题也很容易解决。关键在于,要想清楚块可能会捕获并保留哪些对象。如果这些对象又直接或间接保留了块,那么就要考虑怎样在适当的时机解除引用环。
- 要点:
- 如果块所捕获的对象直接或间接地保留了块本身,那么就得当心循环引用问题。
- 一定要找个适当的时机解除循环引用,而不能把责任推给API的调用者。
41. 多用派发队列,少用同步锁
在Objective-C中,如果有多个线程要执行同一份代码,那么有时可能会出问题。这种情况下,通常要使用锁来实现某种同步机制。在GCD出现之前,有两种办法,第一种是采用内置的“同步块”(synchronization block):1
2
3
4
5
6//第一种方式:@synchronized
-(void)synchronizedMethod{
@synchronized (self) {
//Safe
}
}
这种写法会根据给定的对象,自动创建一个锁,并等待块中的代码执行完毕。执行到这段代码结尾处,锁就释放了。在本例中,同步行为所针对的对象是self。这么写通常没错,因为它可以保证每个对象实例都能不受干扰地运行其synchronizedMethod方法。然而,滥用@synchronized(self)则会降低代码效率,因为共用同一个锁的那些同步块,都必须按顺序执行。若是在self对象上频繁加锁,那么程序可能要等另一段与此无关的代码执行完毕,才能继续执行当前代码,这样做其实并没有必要。
另一个办法是直接使用NSLock对象:1
2
3
4
5
6//第二种方式:NSLock
-(void)synchronizedMethod{
[_lock lock];
//Safe
[_lock unlock];
}
也可以使用NSRecursiveLock这种“递归锁”,线程能够多次持有该锁,而不会出现死锁现象。
这两种方法都很好,不过也有其缺陷。比方说,在极端情况下,同步块会导致死锁,另外,其效率也不见得很高,而如果直接使用锁对象的话,一旦遇到死锁,就会非常麻烦。
替代方案就是使用GCD,它能以更简单、更高效的形式为代码加锁。比方说,属性就是开发者经常需要同步的地方,这种属性需要做成“原子的”。用atomic特质来修饰属性,即可实现这一点(第6条)。而开发者如果想自己来编写访问方法的话,那么通常会这样写:
-(NSString *)someString{
@synchronized (self) {
return _someString;
}
}
-(void)setSomeString:(NSString *)someString{
@synchronized (self) {
_someString = someString;
}
}
滥用@syncronized(self)会很危险,因为所有同步块都会彼此抢夺同一个锁。要是有很多属性都这么写的话,那么每个属性的同步块都要等其他所有同步块执行完毕才能执行,这也许并不是开发者想要的效果。我们只是想令每个属性各自独立地同步。
这么做虽然能提供某种程度的“线程安全”,但却无法保证访问该对象时绝对是线程安全的。当然,访问属性的操作确实是“原子的”。使用属性时,必定能从中获取到有效值,然而在同一个线程上多次调用获取方法,每次获取到的结果却未必相同。在两次访问操作之间,其他线程可能会写入新的属性值。
有种简单而高效的办法可以代替同步块或锁对象,那就是使用“串行同步队列”(serial synchronization queue)。将读取操作及写入操作都安排在同一个队列里,即可保证数据同步。其用法如下:
_syncQueue = dispatch_queue_create("com.effectiveobjectivec.syncQueue", NULL);
-(NSString *)someString{
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
-(void)setSomeString:(NSString *)someString{
dispatch_sync(_syncQueue, ^{
_someString = someString;
});
}
此模式的思路是:把设置操作与获取操作都安排在序列化的队列里执行,这样的话,所有针对属性的访问操作就都同步了。为了使块代码能够设置局部变量,获取方法中用到了__block语法。全部加锁任务都在GCD中处理,而GCD是在相当深的底层来实现的,于是能够做许多优化。
还可以进一步优化,设置方法并不一定非得是同步的。设置实例变量所用的块,并不需要向设置方法返回什么值。也就是说,设置方法的代码可以改成这样:1
2
3
4
5-(void)setSomeString:(NSString *)someString{
dispatch_async(_syncQueue, ^{
_someString = someString;
});
}
这次只是把同步派发改成了异步派发,从调用者的角度来看,这个小改动可以提升设置方法的执行速度,而读取操作与写入操作依然会按顺序执行。但这么改有个坏处:如果你测一下程序性能,那么可能会发现这种写法比原来慢,因为执行异步派发时,需要拷贝块。若拷贝块所用的时间明显超过执行块所花的时间,则这种做法比原来慢。由于这里所举的例子很简单,所以改完之后很可能会变慢。然而,若是派发给队列的块要执行更为繁重的任务,那么仍然可以考虑这种备选方案。
多个获取方法可以并发执行,而获取方法与设置方法之间不能并发执行,利用这个特点,还能写出更快一些的代码来。此时正可以体现出GCD写法的好处。用同步块或锁对象,是无法轻易实现出下面这种方案的。这次不用串行队列,而改用并发队列(concurrent queue):
_syncQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
-(NSString *)someString{
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
-(void)setSomeString:(NSString *)someString{
dispatch_async(_syncQueue, ^{
_someString = someString;
});
}
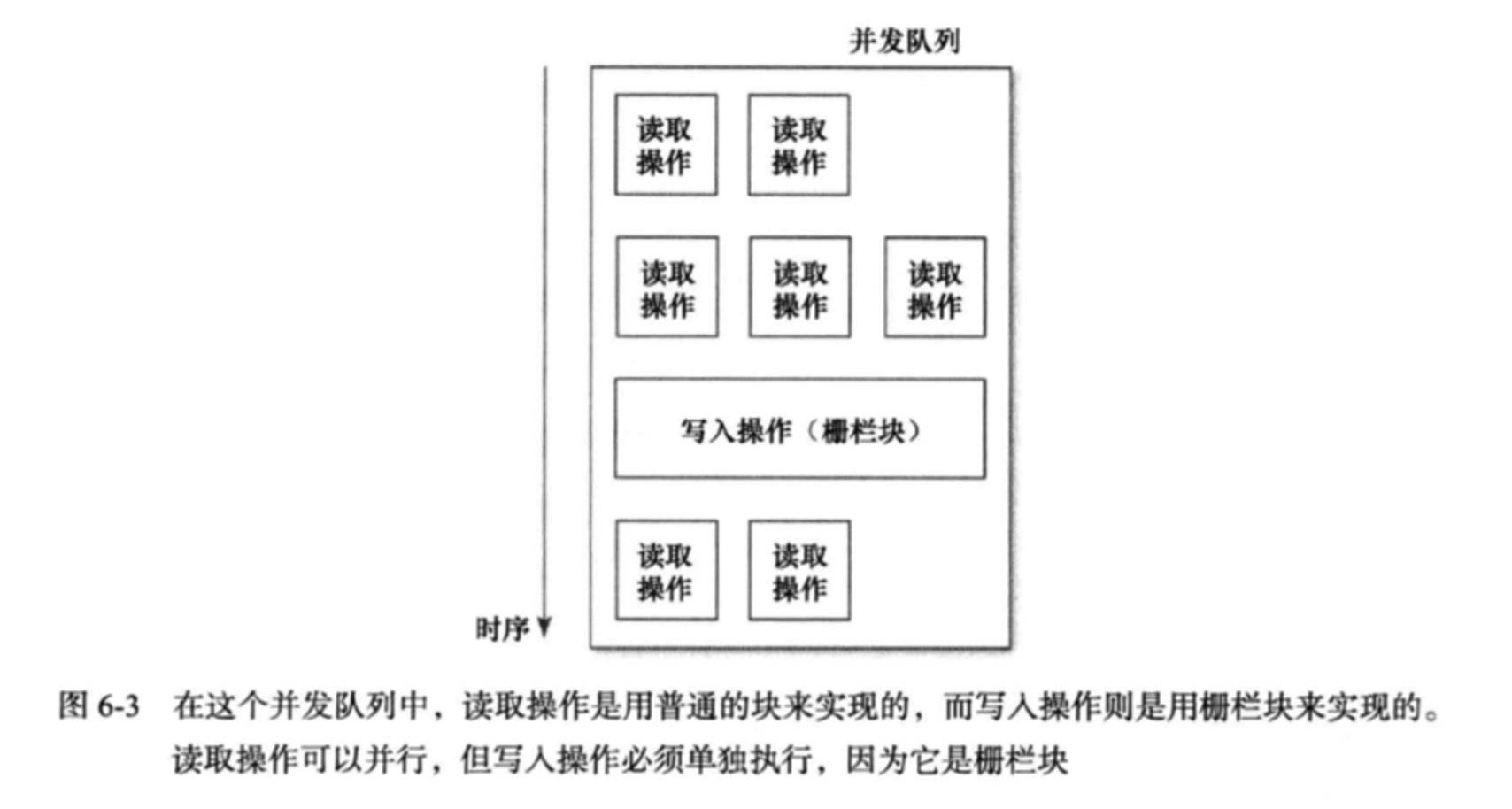
像现在这样写代码,还无法正确实现同步。所有读取操作与写入操作都会在同一个队列上执行,不过由于是并发队列,所以读取与写入操作可以随时执行。而我们恰恰不想让这些操作随意执行。此问题用一个简单的GCD功能即可解决。它就是栅栏(barrier)。下列函数可以向队列中派发块,将其作为栅栏使用:
void dispatch_barrier_async(dispatch_queue_t queue,
dispatch_block_t block);
void dispatch_barrier_sync(dispatch_queue_t queue,
dispatch_block_t block);
在队列中,栅栏块必须单独执行,不能与其他块并行。这只对并发队列有意义,因为串行队列中的块总是按顺序逐个来执行的。并发队列如果发现接下来要处理的块是个栅栏块(barrier block),那么就一直要等当前所有并发块都执行完毕,才会单独执行这个栅栏。待栅栏执行过后,再按正常方式继续向下处理。
在本例中,可以用栅栏块来实现属性的设置方法。在设置方法中使用了栅栏块之后,对属性的读取操作依然可以并发执行,但是写入操作却必须单独执行了。下图演示的这个队列中,有许多读取操作,而且还有一个写入操作:
实现代码:
_syncQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
-(NSString *)someString{
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
-(void)setSomeString:(NSString *)someString{
dispatch_barrier_async(_syncQueue, ^{
_someString = someString;
});
}
这种做法肯定比使用串行队列要快。注意,设置函数也可以改用同步的栅栏块来实现,那样做可能会更高效。最好还是测一测每种做法的性能,然后从中选出最适合当前场景的方案。
- 要点:
- 派发队列可用来表述同步语义,这种做法要比使用@synchronized块或NSLock对象更简单。
- 将同步与异步派发结合起来,可以实现与普通加锁机制一样的同步行为,而这么做却不会阻塞执行异步派发的线程。
- 使用同步队列及栅栏块,可以令同步行为更加高效。
42. 多用GCD,少用performSelector系列方法
Objective-C本质上是一门非常动态的语言,NSObject定义了几个方法,令开发者可以随意调用任何方法。这几个方法可以推迟执行方法调用,也可以指定运行方法所用的线程。这些功能原来很有用,但是在出现了大中枢派发及块这样的新技术之后,就显得不那么必要了。虽然有些代码还是会经常用到它们,但是尽量避开为好。
这其中最简单的是“performSelector:”。该方法的签名如下,它接受一个参数,就是要执行的那个选择子:1
- (id)performSelector:(SEL)aSelector;
该方法与直接调用选择子等效。所以下面两行代码的执行效果相同:1
2[object performSelector:@selector(selectorName)];
[object selectorName];
这种方式看上去似乎多余。如果某个方法只是这么来调用的话,那么此方式确实多余。然而,如果选择子是在运行期决定的,那么就能体现出此方法的强大之处了。这就等于在动态绑定之上再次使用动态绑定,因而可以实现出下面这种功能:1
2
3
4
5
6
7
8
9SEL selecotr;
if(/*some condition*/){
selecotr = @selector(foo);
}else if (/*some other condition*/){
selecotr = @selector(bar);
}else{
selecotr = @selector(baz);
}
[object performSelector:selecotr];
这种编程方式极为灵活,经常可用来简化复杂的代码。还有一种用法,就是先把选择子保存起来,等某个事件发生之后再调用。不管哪种用法,编译器都不知道要执行的选择子是什么,这必须到了运行期才能确定。然而,使用此特性的代价是,如果在ARC下编译代码,那么编译器就会发出如下警告信息:1
2warning:performSelector may cause a leak because its selector
is unknown [-Warc-performSelector-leaks]
原因在于:编译器并不知道将要调用的选择子是什么,因此,也就不了解其方法签名及返回值,甚至连是否有返回值都不清楚。而且,由于编译器不知道方法名,所以就没办法运用ARC的内存管理规则来判定返回值是不是应该释放。鉴于此,ARC采用了比较谨慎的做法,就是不添加释放操作。然而这么做可能导致内存泄露,因为方法在返回对象时可能已经将其保留了。
考虑下面这段代码:1
2
3
4
5
6
7
8
9SEL selecotr;
if(/*some condition*/){
selecotr = @selector(newObject);
}else if (/*some other condition*/){
selecotr = @selector(copy);
}else{
selecotr = @selector(someProperty);
}
id ret = [object performSelector:selecotr];
如果调用的是前两个选择子之一,那么ret对象应由这段代码来释放,而如果是第三个选择子,则无须释放。不仅在ARC环境下应该如此,而在在非ARC环境下也应该这么做,这样才算严格遵循了方法的命名规范。如果不使用ARC(此时编译器就不发警告信息了),那么在前两种情况下需要手动释放ret对象,而在后一种情况下则不需要释放。这个问题很容易忽视,而且就算用静态分析器,也很难侦测到随后的内存泄露。performSelector系列的方法之所以要谨慎使用,这就是其中一个原因。
这些方法不甚理想,另一个原因在于:返回值只能是void或对象类型。尽管所要执行的选择子也可以返回void,但是performSelector方法的返回值类型毕竟是id。如果想返回整数或浮点等类型的值,那么就需要执行一些复杂的转换操作了,而这种转换很容易出错。由于id类型表示指向任意Objective-C对象的指针,所以从技术上来讲,只要返回值的大小和指针所占大小相同就行,也就是说:在32位架构的计算机上,可以返回任意32位大小的类型;而在64位架构的计算机上,则可返回任意64位大小的类型。若返回值的类型为C语言结构体,则不可使用performSelector方法。
performSelector还有如下几个版本,可以在发消息时顺便传递参数:1
2- (id)performSelector:(SEL)aSelector withObject:(id)object;
- (id)performSelector:(SEL)aSelector withObject:(id)object1 withObject:(id)object2;
这些方法貌似有用,但其实局限颇多。由于参数类型是id,所以传入的参数必须是对象才行。如果选择子所接受的参数是整数或浮点数,那就不能采用这些方法了。此外,选择子最多只能接受两个参数,也就是调用“performSelector: withObject: withObject:”这个版本。而在参数不止两个的情况下,则没有对应的performSelector方法能够执行此种选择子。
performSelector系列方法还有个功能,就是可以延后执行选择子,或将其放在另一个线程上执行。下面列出了此方法中一些更为常用的版本:
1 | - (void)performSelector:(SEL)aSelector withObject:(nullable id)anArgument afterDelay:(NSTimeInterval)delay; |
然而很快就会发觉,这些方法太过局限了。例如,具备延后执行功能的那些方法都无法处理带有两个参数的选择子。而能够指定执行线程的那些方法,则与之类似,所以也不是特别通用。如果要用这些方法,就得把许多参数都打包到字典中,然后在受调用的方法里将其提取出来,这样会增加开销,而且还可能出bug。
如果改用其他替代方案,那就不受这些限制了。最主要的替代方案就是使用块。而且,performSelector系列方法所提供的线程功能,都可以通过在大中枢派发机制中使用块来实现。延后执行可以用dispatch_after来实现,在另一个线程上执行任务则可以通过dispatch_sync及dispatch_async来实现。
例如,要延后执行某项任务,可以有下面两种实现方式,而我们应该优先考虑第二种:
//Using performSelector:withObject:afterDelay:
[self performSelector:@selector(doSomething) withObject:nil afterDelay:5.0];
//Using dispatch_after
dispatch_time_t time = dispatch_time(DISPATCH_TIME_NOW, (int64_t)(5.0*NSEC_PER_SEC));
dispatch_after(time, dispatch_get_main_queue(), ^{
[self doSomething];
});
想把任务放在主线程上执行,也可以有下面两种方式,而我们还是应该优选后者:
//Using performSelectorOnMainThread: withObject: waitUntilDone:
[self performSelectorOnMainThread:@selector(doSomething) withObject:nil waitUntilDone:NO];
//Using dispatch_async
//(or if waitUntilDone is YES, then dispatch_sync)
dispatch_async(dispatch_get_main_queue(), ^{
[self doSomething];
});
waitUntilDone为NO时相当于使用dispatch_async;waitUntilDone为YES时相当于使用dispatch_sync。
- 要点:
- performSelector系列方法在内存管理方面容易有疏失。它无法确定将要执行的选择子具体是什么,因而ARC编译器也就无法插入适当的内存管理方法。
- performSelector系列方法所能处理的选择子太过局限了,选择子的返回值类型及发送给方法的参数个数都受到限制。
- 如果想把任务放在另一个线程上执行,那么最好不要用performSelector系列方法,而是应该把任务封装到块里,然后调用大中枢派发机制的相关方法来实现。
43. 掌握GCD及操作队列的使用时机
很少有其他技术能与GCD的同步机制相媲美。对于那些只需执行一次的代码来说,也是如此,使用GCD的dispatch_once最为方便。然而,在执行后台任务时,GCD并不一定是最佳方式。还有一种技术叫做NSOperationQueue,它虽然与GCD不同,但是却与之相关,开发者可以把操作以NSOperation子类的形式放在队列中,而这些操作也能够并发执行。其与GCD派发队列有相似之处,这并非巧合。“操作队列”(operation queue)在GCD之前就有了,其中某些设计原理操作队列而流行,GCD就是基于这些原理构建的。实际上,从iOS4与Mac OS X 10.6开始,操作队列在底层是用GCD来实现的。
在两者的诸多差别中,首先要注意:GCD是纯C的API,而操作队列则是Objective-C的对象。在GCD中,任务用块来表示,而块是个轻量级数据结构。与之相反,“操作”(operation)则是个更为重量级的Objective-C对象。虽说如此,但GCD并不总是最佳方案。有时候采用对象所带来的开销微乎其微,使用完整对象所带来的好处反而大大超过其缺点。
使用NSOperationQueue类的“addOperationWithBlock:”方法搭配NSBlockOperation类来使用操作队列,其语法与纯GCD方式非常相似。
- 使用NSOperation及NSOperationQueue的好处如下:
- 取消某个操作。如果使用操作队列,那么想要取消操作是很容易的。运行任务之前,可以在NSOperation对象上调用cancel方法,该方法会设置对象内的标志位,用以表明此任务不需执行,不过,已经启动的任务无法取消。若是不是使用操作队列,而是把块安排到GCD队列,那就无法取消了。那套架构是“安排好任务之后就不管了”(fire and forget)。开发者可以在应用程序层自己来实现取消功能,不过这样做需要编写很多代码,而那些代码其实已经由操作队列实现好了。
- 指定操作间的依赖关系。一个操作可以依赖其他多个操作。开发者能够指定操作之间的依赖体系,使特定的操作必须在另外一个操作顺利执行完毕后方可执行。比方说,从服务器端下载并处理文件的动作,可以用操作来表示,而在处理其他文件之前,必须先下载“清单文件”(manifest file)。后续的下载操作,都要依赖于先下载清单文件这一操作。如果操作队列允许并发的话,那么后续的多个下载操作就可以同时执行,但前提是它们所依赖的那个清单文件下载操作已经执行完毕。
- 通过键值观测机制监控NSOperation对象的属性。NSOperation对象有许多属性都适合通过键值观测机制(KVO)来监听,比如可以通过isCancelled属性来判断任务是否已取消,又比如可以通过isFinished属性来判断任务是否已完成。如果想在某个任务变更其状态时得到通知,或是想用比GCD更为精细的方式来控制所要执行的任务,那么键值观测机制会很有用。
- 指定操作的优先级。操作的优先级表示此操作与队列中的其他操作之间的优先级关系。优先级高的操作先执行,优先级低的后执行。操作队列的调度算法虽“不透明”,但必然是经过一番深思熟虑才写成的。反之,GCD则没有直接实现此功能的办法。GCD的队列确实有优先级,不过那是针对整个队列来说的,而不是针对每个块来说的。而令开发者在GCD之上自己来编写调度算法,又不太合适。因此,在优先级这一点上,操作队列所提供的功能要比GCD更为便利。NSOperation对象也有“线程优先级”(thread priority),这决定了运行此操作的线程处在何种优先级上。用GCD也可以实现此功能,然而采用操作队列更简单,只需设置一个属性。
- 重用NSOperation对象。系统内置了一些NSOperation的子类(比附NSBlockOperation)供开发者调用,要是不想用这些固有子类的话,那就得自己来创建了。这些类就是普通的Objective-C对象,能够存放任何信息。对象在执行时可以充分利用存放于其中的信息,而且还可以随意调用定义在类中的方法。这就比派发队列中那些简单的块要强大许多。这些NSOperation类可以在代码中多次使用,它们符合软件开发中的“不重复”(Don’t Repeat Yourself,DRY)原则。
- 操作队列有很多地方胜过派发队列。操作队列提供了多种执行任务的方式,而且都是写好了的,直接就能使用。开发者不用再编写复杂的调度器,也不用自己来实现取消操作或者指定操作优先级的功能,这些事情操作队列都已经实现好了。
有一个API选用了操作队列而非派发队列,这就是NSNotificationCenter,开发者可通过其中的方法来注册监听器,以便在发生相关事件时得到通知,而这个方法接受的参数是块,不是选择子。方法原型如下:
1 | - (id <NSObject>)addObserverForName:(nullable NSString *)name |
- 要点:
- 在解决多线程与任务管理问题时,派发队列并非唯一方案。
- 操作队列提供了一套高层的Objective-C API,能实现纯GCD所具备的绝大部分功能,而且还能完成一些更为复杂的操作,那些操作若改用GCD来实现,则需另外编写代码。
44. 通过Dispatch Group机制,根据系统资源状况来执行任务
dispatch group(派发分组,调度组)是GCD的一项特性,能够把任务分组。调用者可以等待这组任务执行完毕,也可以在提供回调函数之后继续往下执行,这组任务完成时,调用者会得到通知。这个功能有许多用途,其中最重要、最值得注意的用法,就是把将要并发执行的多个任务合为一个组,于是调用者就可以知道这些任务何时才能全部执行完毕。比方说,可以把压缩一系列文件的任务表示成dispatch group。
下面这个函数可以创建dispatch group:dispatch_group_t dispatch_group_create(void);
dispatch group就是一个简单的数据结构,这种数据结构彼此之间没什么区别,它不像派发队列,后者还有个用来区别身份的标识符。
想把任务编组,有两种办法。第一种是用下面这个函数:1
void dispatch_group_async(dispatch_group_t group, dispatch_queue_t queue, dispatch_block_t block);
它是普通dispatch_async函数的变体,比原来多一个参数,用于表示待执行的块所属的组。还有种办法能够指定任务所属的dispatch group,那就是使用下面这一对函数:1
2void dispatch_group_enter(dispatch_group_t group);
void dispatch_group_leave(dispatch_group_t group);
前者能够使分组里正要执行的任务数递增,而后者则使之递减。由此可知,调用了dispatch_group_enter以后,必须有与之对应的dispatch_group_leave才行。这与引用计数相似,要使用引用计数,就必须令保留操作与释放操作彼此对应,以防内存泄露。而在使用dispatch_group时,如果调用enter之后,没有相应的leave操作,那么这一组任务就永远执行不完。
下面这个函数可用于等待dispatch group执行完毕:
1 | long dispatch_group_wait(dispatch_group_t group, dispatch_time_t timeout); |
此函数接受两个参数,一个是要等待的group,另一个是代表等待时间的timeout值。timeout参数表示函数在等待dispatch group执行完毕时,应该阻塞多久。如果执行dispatch group所需的时间小于timeout,则返回0,否则返回非0值。此函数也可以取常量DISPATCH_TIME_FOREVER,这表示函数会一直等着dispatch group执行完,而不会超时。
除了可以用上面那个函数等待dispatch group执行完毕之外,也可以换个办法,使用下列函数:
1 | void dispatch_group_notify(dispatch_group_t group, dispatch_queue_t queue, dispatch_block_t block); |
与wait函数略有不同的是:开发者可以向此函数传入块,等dispatch group执行完毕之后,块会在特定的线程上执行。假如当前线程不应阻塞,而开发者又想在那些任务全部完成时得到通知,那么此做法就很有必要了。比方说,在Mac OS X与iOS系统中,都不应阻塞主线程,因为所有UI绘制及事件处理都要在主线程上执行。
如果想令数组中的每个对象都执行某项任务,并且想等待所有任务执行完毕,那么就可以使用这个GCD特性来实现。代码如下:
dispatch_queue_t queue = dispatch_queue_create(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_group_t dispatchGroup = dispatch_group_create();
for(id object in collection){
dispatch_group_async(dispatchGroup, queue, ^{
[object performTask];
});
}
dispatch_group_wait(dispatchGroup, DISPATCH_TIME_FOREVER);
//Continue processing after completing tasks
若当前线程不应阻塞,则可以用notify函数来取代wait:
dispatch_queue_t notifyQueue = dispatch_get_main_queue();
dispatch_group_notify(dispatchGroup, notifyQueue, ^{
//Continue processing after completing tasks
});
notify回调时所选用的队列,完全应该根据具体情况来定。这里使用了主队列,这是种常见写法,也可以用自定义的串行队列或全局并发队列。
本例中,所有任务都派发到同一个队列之中。但实际上未必一定要这样做。也可以把某些任务放在优先级高的线程上执行,同时仍然把所有任务都归入同一个dispatch group,并在执行完毕时获得通知:
dispatch_queue_t lowPriorityQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0);
dispatch_queue_t highPriorityQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0);
dispatch_group_t dispatchGroup = dispatch_group_create();
for(id object in lowPriorityObjects){
dispatch_group_async(dispatchGroup, lowPriorityQueue,^{
[object performTask];
});
}
for(id object in highPriorityObjects){
dispatch_group_async(dispatchGroup, highPriorityQueue,^{
[object performTask];
});
}
dispatch_queue_t notifyQueue = dispatch_get_main_queue();
dispatch_group_notify(dispatchGroup, notifyQueue, ^{
//Countinue processing after completing tasks
});
除了像上面这样把任务提交到并发队列之外,也可以把任务提交至各个串行队列中,并用dispatch group跟踪其执行状况。然而,如果所有任务都排在同一个串行队列里面,那么dispatch group就用处不大了。因为此时任务总要逐个执行,所以只需在提交完全部任务之后再提交一个块即可,这样做与通过notify函数等待dispatch group执行完毕然后再回调块是等效的:
dispatch_queue_t queue = dispatch_queue_create("com.effectiveobjectivec.queue", NULL);
for(id object in collections){
dispatch_async(queue, ^{
[object performTask];
});
}
dispatch_async(queue, ^{
//Continue processing after completing tasks
});
上面这段代码表明,开发者未必总是需要使用dispatch group。有时候采用单个队列搭配标准的异步派发,也可以实现同样效果。
为了执行队列中的块,GCD会在适当的时机自动创建新线程或复用旧线程。如果使用并发队列,那么其中有可能会有多个线程,这也就意味着多个块可以并发执行。在并发队列中,执行任务所用的并发线程数量,取决于各种因素,而GCD主要是根据系统资源状况来判断这些因素的。加入CPU有多个核心,并发队列中有大批任务等待执行,那么GCD就可能会给该队列配置多个线程。通过dispatch group所提供的这种简便方式,既可以并发执行一系列给定的任务,又能在全部任务结束时得到通知。由于GCD有并发队列机制,所以能够根据可用的系统资源状况来并发执行任务。而开发者则可用专注于业务逻辑代码,无须再为了处理并发任务而编写复杂的调度器。
在前面的例子中,我们遍历某个collection,并在其每个元素上执行任务,而这也可以用另外一个GCD函数来实现:1
void dispatch_apply(size_t iterations, dispatch_queue_t queue, void (^block)(size_t));
此函数会将块反复执行一定的次数,每次传给块的参数值都会递增,从0开始,直至”iterations-1“。其用法如下:1
2
3
4dispatch_queue_t queue = dispatch_queue_create("com.effectiveobjectivec.queue", NULL);
dispatch_apply(10, queue, ^(size_t i) {
//Perform task
});
采用简单的for循环,从0递增至9,也能实现同样的效果:1
2
3for(int i=0;i<10;i++){
//Perform task
}
注意:dispatch_apply所用的队列可以是并发队列。如果采用并发队列,那么系统就可以根据资源状况来并行执行这些块了,这与使用dispatch group的那段代码一样。上面这个for循环要处理的collection若是数组,则可以用dispatch_apply改写成:
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply(array.count, queue, ^(size_t i) {
id object = array[i];
[object performTask];
});
这个例子再次表明:未必总要使用dispatch_group。然而,dispatch_apply会持续阻塞,直到所有任务都执行完毕未知。由此可见:假如把块派发给了当前队列(或者体系中高于当前队列的某个串行队列),将导致死锁。若想在后台执行任务,则应使用dispatch group。
- 要点:
- 一系列任务可归入一个dispatch group之中。开发者可以在这组任务执行完毕时获得通知。
- 通过dispatch group,可以在并发式派发队列里同时执行多项任务。此时GCD会根据系统资源状况来调度这些并发执行的任务。
45. 使用dispatch_once来执行只需运行一次的线程安全的代码
单例模式(singleton)对Objective-C开发者来说并不陌生,常见的实现方式为:在类中编写名为sharedInstance的方法,该方法只会返回全类共用的单例实例,而不会在每次调用时都创建新的实例。假设有个类叫EOCClass,那么这个共享实例的方法一般都会这样写:1
2
3
4
5
6
7
8
9+(instancetype)sharedInstance{
static EOCClass *sharedInstance = nil;
@synchronized (self) {
if(!sharedInstance){
sharedInstance = [[self alloc]init];
}
}
return sharedInstance;
}
为保证线程安全,上述代码将创建单例实例的代码包裹在同步块里。
不过,GCD引入了一项特性,能使单例实现起来更为容易。所用的函数是:1
void dispatch_once(dispatch_once_t *predicate, dispatch_block_t block);
此函数接受类型为dispatch_once_t的特殊参数,作者称其为“标记”(token),此外还接受块参数。对于给定的标记来说,该函数保证相关的块必定会执行,且仅执行一次。首次调用该函数时,必然会执行块中的代码,最重要的一点在于,此操作完全是线程安全的。请注意,对于只需执行一次的块来说,每次调用函数时传入的标记都必须完全相同。因此,开发者通常将标记变量声明在static或global作用域里。
刚才实现单例模式所用的sharedInstance方法,可以用此函数来改写:1
2
3
4
5
6
7
8+(instancetype)sharedInstance{
static EOCClass *sharedInstance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
sharedInstance = [[self alloc]init];
});
return sharedInstance;
}
使用dispatch_once可以简化代码并且彻底保证线程安全,开发者根本无须担心加锁或同步。所有问题都由GCD在底层处理。由于每次调用时都必须使用完全相同的标记,所以标记要声明称static。把该变量定义在static作用域里,可以保证编译器在每次执行sharedInstance方法时都会复用这个变量,而不会创建新变量。
此外,dispatch_once更高效。它没有使用重量级的同步机制,若是那样的话,每次运行代码钱都要获取锁,相反,此函数采用“原子访问”(atomic access)来查询标记,以判断其所对应的代码原来是否已经执行过。
- 要点:
- 经常需要编写“只需执行一次的线程安全代码”(thread-safe single-code execution)。通过GCD所提供的dispatch_once函数,很容易就能实现此功能。
- 标记应该声明在static或global作用域中,这样的话,在把只需执行一次的块传给dispatch_once函数时,传进去的标记也是相同的。
46. 不要使用dispatch_get_current_queue
使用GCD时,经常需要判断当前代码正在哪个队列上执行,向多个队列派发任务时,更是如此。1
2// 此函数返回当前正在执行代码的队列,不过用的时候要小心。从iOS系统6.0版本起,已经将其废弃了。
dispatch_queue_t dispatch_get_current_queue(void);
该函数有种典型的错误用法(antipattern,“反模式”),就是用它检测当前队列是不是某个特定的队列,试图以此来避免执行同步派发时可能遭遇的死锁问题。考虑下面这两个存取方法,其代码用队列来保证对实例变量的访问操作是同步的:
-(NSString *)someString{
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
-(void)setSomeString:(NSString *)someString{
dispatch_async(_syncQueue, ^{
_someString = someString;
});
}
这种写法的问题在于,获取方法可能会死锁,假如调用获取方法的队列恰好是同步操作所针对的队列(本例中是_syncQueue),那么dispatch_sync就一直不会返回,直到块执行完毕为止。可是,应该执行块的那个目标队列却是当前队列,而当前队列的dispatch_sync又一直阻塞着,它在等待目标队列把这个块执行完,这样一来,块就永远没机会执行了。像someString这种方法,就是“不可重入的”。
看了dispatch_get_current_queue的文档后,你也许会觉得可以用它改写这个方法,令其变得“可重入”,只需检测当前队列是否为同步操作所针对的队列,如果是,就不派发了,直接执行块即可:
-(NSString *)someString{
__block NSString *localSomeString;
dispatch_block_t accessorBlock = ^{
localSomeString = _someString;
};
if(dispatch_get_current_queue()==_syncQueue){
accessorBlock();
}else{
dispatch_sync(_syncQueue, accessorBlock);
}
return localSomeString;
}
这种做法可以处理一些简单情况。不过仍然有死锁的危险。为说明其原因,考虑下面这段代码,其中有两个串行派发队列:1
2
3
4
5
6
7
8
9dispatch_queue_t queueA = dispatch_queue_create("com.effectiveobjectivec.queueA", NULL);
dispatch_queue_t queueB = dispatch_queue_create("com.effectiveobjectivec.queueB", NULL);
dispatch_sync(queueA, ^{
dispatch_sync(queueB, ^{
dispatch_sync(queueA, ^{
//Deadlock
});
});
});
这段代码执行到最内层的派发操作时,总会死锁,因为此操作是针对queueA队列的,所以必须等最外层的dispatch_sync执行完毕才行,而最外层的那个dispatch_sync又不可能执行完毕,因为它要等最内层的dispatch_sync执行完,于是就死锁了。现在按照刚才的办法,使用dispatch_get_current_queue来检测:1
2
3
4
5
6
7
8
9
10dispatch_sync(queueA, ^{
dispatch_sync(queueB, ^{
dispatch_block_t block = ^{/*...*/};
if(dispatch_get_current_queue()==queueA){
block();
}else{
dispatch_sync(queueA, block);
}
});
});
然而这样做依然死锁,因为dispatch_get_current_queue返回的是当前队列,在本例中就是queueB。这样的话,针对queueA的同步派发操作依然会执行,于是和刚才一样,还是死锁了。
在这种情况下,正确的做法是:不要把存取方法做成可重入的,而是应该确保同步操作所用的队列绝不会访问属性,也就是绝不会调用someString方法。这种队列只应该用来同步属性。由于派发队列是一种极为轻量级的机制,所以,为了确保每项属性都有专用的同步队列,我们不妨创建多个队列。
使用队列时还要注意另外一个问题,而那个问题会在你意想不到的地方导致死锁。队列之间会形成一套层级体系,这意味着排在某条队列中的块,会在其上级队列(parent queue,也叫“父队列”)里执行。层级里地位较高的那个队列总是“全局并发队列”。下图描述了一套简单的队列体系:
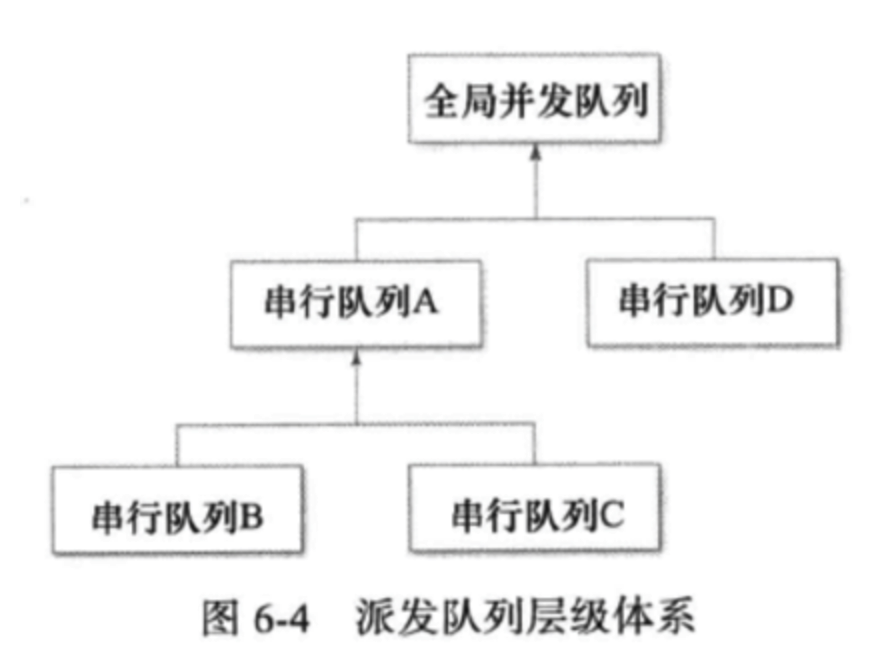
排在队列B或队列C中的块,稍后会在队列A里依次执行。于是,排在队列A、B、C中的块总是要彼此错开执行。然而,安排在队列D中的块,则有可能与队列A里的块(也包括队列B与C里的块)并行,因为A与D的目标队列是个并发队列。若有必要,并发队列可以用多个线程并行执行多个块,而是否会这样做,则需根据CPU的核心数量等系统资源状况来定。
由于队列见有层级关系,所以“检查当前队列是否为执行同步派发所用的队列”这种办法,并不总是奏效。比方说,排在队列C里的块,会认为当前队列就是队列C,而开发者可能会据此认为:在队列A上能够安全地执行同步派发操作。但实际上,这么做依然会像前面那样导致死锁。
有的API可令开发者指定运行回调块时所用的队列,但实际上却把回调块安排在内部的串行同步队列上,而内部队列的目标队列又是开发者所提供的那个队列,在此情况下,也许就要出现刚才说的那种问题了。使用这种API的开发者可能误以为:在回调块里调用dispatch_get_current_queue所返回的“当前队列”,总是其调用API时指定的那个。但实际上返回的却是API内部的那个同步队列。
要解决这个问题,最好的办法就是通过GCD所提供的功能来设定“队列特有数据”(queue-specific data),此功能可以把任意数据以键值对的形式关联到队列里。最重要之处在于,假如根据指定的键获取不到关联数据,那么系统就会沿着层级体系向上查找,直至找到数据或到达根队列为止。看下面这个例子:
dispatch_queue_t queueA = dispatch_queue_create("com.effectiveobjectivec.queueA", NULL);
dispatch_queue_t queueB = dispatch_queue_create("com.effectiveobjectivec.queueB", NULL);
static int kQueueSpecific;
CFStringRef queueSpecificValue = CFSTR("queueA");
dispatch_queue_set_specific(queueA,
&kQueueSpecific,
(void*)queueSpecificValue,
(dispatch_function_t)CFRelease);
dispatch_sync(queueB, ^{
dispatch_block_t block = ^{NSLog(@"No deadlock!");};
CFStringRef retrievedValue = dispatch_get_specific(&kQueueSpecific);
if(retrievedValue){
block();
}else{
dispatch_sync(queueA, block);
}
});
本例创建了两个队列。代码中将队列B的目标队列设为队列A,而队列A的目标队列仍然是默认优先级的全局并发队列。然后使用下列函数,在队列A上设置“队列特定值”:1
2
3
4void dispatch_queue_set_specific(dispatch_queue_t queue,
const void *key,
void *context,
dispatch_function_t destructor);
此函数的首个参数表示待设置数据的队列,其后两个参数是键与值。键与值都是不透明的void指针。对于键来说,有个问题一定要注意:函数是按指针值来比较键的,而不是按照其内容。所以,“队列特定数据”更像是“关联引用”。值(在函数中原型里叫context)也是不透明的void指针,于是可以在其中存放任意数据。然而,必须管理该对象的内存。这使得在ARC环境下很难使用Objective-C对象作为值。范例代码使用CoreFoundation字符串作为值,因为ARC并不会自动管理CoreFoundation对象的内存。所以说,这种对象非常适合充当“队列特定数据”,它们可以根据需要与相关的Objective-C Foundation类无缝衔接。
函数最后一个参数是“析构函数”,对于给定的键来说,当队列所占内存为系统所回收,或者有新的值与键相关联时,原有的值对象就会移除,而析构函数也会与于此时执行。dispatch_function_t类的定义如下:1
typedef void (*dispatch_function_t)(void *);
由此可知,析构函数只能带有一个指针参数且返回值必须为void。范例代码采用CFRelease做析构函数,此函数符合要求,不过也可以采用开发者自定义的函数,在其中调用CFRelease以清理旧值,并完成其他必要的清理工作。
于是,“队列特定数据”所提供的这套简单易用的机制,就避免了使用dispatch_get_current_queue时经常遭遇的一个陷阱。此外,调试程序时也许会经常用到dispatch_get_current_queue。在此情况下,可以放心使用这个已经废弃的方法,只是别把它编译到发行版的程序里就行。
- 要点:
- dispatch_get_current_queue函数的行为常常与开发者所预期的不同。此函数已经废弃,只应做调试之用。
- 由于派发队列是按层级来组织的,所以无法单用某个队列对象来描述“当前队列”这一概念。
- dispatch_get_current_queue函数用于解决由不可重入的代码所引发的死锁,然而能用此函数解决的问题,通常也能改用“队列特定数据”来解决。
———————————————————-
七、系统框架
47. 熟悉系统框架
将一系列代码封装为动态库(dynamic library),并在其中放入描述其接口的头文件,这样做出来的东西就叫框架。有时为iOS平台构建的第三方框架所使用的是静态库(static library),这是因为iOS应用程序不允许在其中包含动态库。这些东西严格来讲并不是真正的框架,然而也经常视为框架。不过,所有iOS平台的系统框架仍然使用动态库。
在为Mac OS X或iOS系统开发“带图形界面的应用程序”时,会用到名为Cocoa的框架,在iOS上成为Cocoa Touch。其实Cocoa本身并不是框架,但是里面继承了一批创建应用程序时经常会用到的框架。
开发者会碰到的主要框架就是Foundation,像是NSObject、NSArray、NSDictionary等类都在其中。Foundation框架是所有Objective-C应用程序的“基础”。
Foundation框架不仅提供了collection等基础核心功能,而且还提供了字符串处理这样的复杂功能。比方说,NSLinguisticTagger可以解析字符串并找到其中的全部名词、动词、代词等。
还有个与Foundation相伴的框架,叫做CoreFoundation。虽然从技术上讲,CoreFoundation框架不是Objective-C框架,但它确实编写Objective-C应用程序所应熟悉的重要框架,Foundation框架中的许多功能,都可以在此框架中找到对应的C语言API。CoreFoundation与Foundation不仅名字相似,而且还有更为紧密的联系。有个功能叫做“无缝桥接”(toll-free bridging),可以把CoreFoundation中的C语言数据结构平滑转换为Foundation中的Objective-C对象,也可以反向转换。比方说,Foundation框架中的字符串是NSString,而它可以转换为CoreFoundation里与之等效的CFString对象。无缝桥接技术是用某些相当复杂的代码实现出来的,这些代码可以使运行期系统把CoreFoundation框架中的对象视为普通的Objective-C对象。
除了Foundation与CoreFoundation之外,还有很多系统库,其中包括但不限于下面列出的这些:
- `CFNetwork:` 此框架提供了C语言级别的网络通信能力,它将“BSD套接字”(BSD socket)抽象成易于使用的网络接口。而Foundation则将该框架里的部分内容封装为Objective-C语言的接口,以便进行网络通信,例如可以用NSURLConnection从URL下载数据。
- `CoreAudio:` 该框架所提供的C语言API可用来操作设备上的音频文件。这个框架属于比较难用的,因为音频处理本身就很复杂。所幸由这套API可以抽象出另外一套Objective-C式API,用后者来处理音频问题会更简单些。
- `CoreData:` 此框架所提供的Objective-C接口可将对象放入数据库,便于持久保存。CoreData会处理数据的获取及存储事宜,而且可以跨越Mac OS X及iOS平台。
- `CoreText:` 此框架提供的C语言接口可以高效执行文字排版及渲染操作。
Objective-C编程时会经常需要使用底层的C语言级API。用C语言来实现API的好处是, 可以绕过Objective-C的运行期系统,从而提升执行速度。当然,由于ARC只负责Objective-C的对象,所以使用这些API时尤其要注意内存管理问题。
Mac OS X与iOS平台的核心UI框架分别叫AppKit及UIKit,它们都提供了构建在Foundation与CoreFoundation之上的Objective-C类。在这些主要的UI框架之下,是CoreAnimation与CoreGraphics框架。
CoreAnimation是用Objective-C语言写成的,它提供了一些工具,而UI框架则用这些工具来渲染图形并播放动画。CoreAnimation本身并不是框架,它是QuartzCore框架的一部分。
CoreGraphics框架是用C语言写成的,其中提供了2D渲染所必备的数据结构与函数。例如,其中定义了CGPoint、CGSize、CGRect等数据结构,而UIKit框架中的UIView类在确定视图控件之间的相对位置时,这些数据结构都要用到。
还有很多框架构建在UI框架之上,比如MapKit框架,它为iOS程序提供地图功能。又比如Social框架,它为Mac OS X及iOS程序提供了社交网络功能。
- 要点:
- 许多系统框架都可以直接使用。其中最重要的是Foundation与CoreFoundation,这两个框架提供了构建应用程序所需的许多核心功能。
- 很多常见任务都能用框架来做,例如音频与视频处理、网络通信、数据管理等。
- 请记住:用纯C写成的框架与用Objective-C写成的一样重要,若想要成为优秀的Objective-C开发者,应该掌握C语言的核心概念。
48. 多用块枚举,少用for循环
在编程中经常需要列举collection中的元素,当前的Objective-C语言有很多种办法实现此功能,可以用标准的C语言循环,也可以用Objective-C 1.0的NSEnumerator以及Objective-C 2.0的快速遍历。语言中引入“块”这一特性后,又多出来几种新的遍历方式,采用这几种新方式遍历collection时,可以传入块,而collection中的每个元素都可能会放在块里运行一遍,这种做法通常会大幅度简化编码过程。
- 使用Objective-C 1.0的NSEnumerator来遍历
NSEnumerator是个抽象基类,其中只定义了两个方法,供其具体子类来实现:1
2- (NSArray*)allObjects;
- (nullable ObjectType)nextObject;
其中关键的方法是nextObject,它返回枚举里的下个对象。每次调用该方法时,其内部数据结构都会更新,使得下次调用方法时能返回下个对象。等到枚举中的全部对象都已返回之后,再调用就将返回nil,这表示达到枚举末端了。
- 快速遍历
Objective-C 2.0引入了快速遍历这一功能。它为for循环开设了in关键字。这个关键字大幅简化了遍历collection所需的语法。
如果某个类的对象支持快速遍历,那么就可以宣称自己遵从名为NSFastEnumeration的协议,从而令开发者可以采用此语法来迭代该对象。此协议只定义了一个方法:1
2
3- (NSUInteger)countByEnumeratingWithState:(NSFastEnumerationState *)state
objects:(id __unsafe_unretained [])buffer
count:(NSUInteger)len;
该方法允许类实例同时返回多个对象,这就使得循环遍历操作更为高效了。
- 基于块的遍历方式
在当前的Objective-C语言中,最新引入的一种做法就是基于块来遍历。NSArray中定义了下面这个方法,它可以实现最基本的遍历功能:1
2- (void)enumerateObjectsUsingBlock:
- (void (^)(ObjectType obj, NSUInteger idx, BOOL *stop))block ;
此方法提供了一种优雅的机制,用于终止遍历操作,开发者可以通过设定stop变量值来实现。1
2
3- (void)enumerateObjectsWithOptions:(NSEnumerationOptions)opts usingBlock:(void (^)(ObjectType obj, NSUInteger idx, BOOL *stop))block;
- (void)enumerateKeysAndObjectsWithOptions:(NSEnumerationOptions)opts usingBlock:(void (^)(KeyType key, ObjectType obj, BOOL *stop))block;
NSEnumerationOptions类型是个enum,其各种取值可用“按位或”连接,用以表明遍历方式。例如,开发者可以请求以并发方式执行各轮迭代,也就是说,如果当前系统资源状况允许,那么执行每次迭代所用的块就可以并行执行了。通过NSEnumerationConcurrent选项即可开启此功能。如果使用此选项,那么底层会通过GCD来处理并发执行事宜,具体实现时很可能会用到dispatch group。反向遍历是通过NSEnumerationReverse选项来实现的。
总体来看,块枚举法拥有其他遍历方式都具备的又是,而且还能带来更多好处。与快速遍历法相比,它更多用一些代码,可是却能提供遍历时所针对的下标,在遍历字典时也能同时提供键与值,而且还有选项可以开启并发迭代功能。
- 要点:
- 遍历collection有四种方式。最基本的办法是for循环,其次是NSEnumerator遍历法及快速遍历法,最新、最先进的方式则是“块枚举法”。
- “块枚举法”本身就能通过GCD来并发执行遍历操作,无须另行编写代码。而采用其他遍历方式则无法轻易实现这一点。
- 若提前知道待遍历的collection含有何种对象,则应修改块签名,指出对象的具体类型。
49. 对自定义其内存管理语义的collection使用无缝桥接
使用“无缝桥接”技术,可以在定义于Foundation框架中的Objective-C类和定义与CoreFoundation框架中的C数据结构之间互相转换。
下列代码演示了简单的无缝桥接:1
2
3NSArray *anNSArray = @[@1,@2,@3,@4,@5];
CFArrayRef aCFArray = (__bridge CFArrayRef)anNSArray;
NSLog(@"Size of array = %li",CFArrayGetCount(aCFArray));
__bridge告诉ARC如何处理转换所涉及的Objective-C对象。bridge本身的意思是:ARC仍然具备这个Objective-C对象的所有权。而bridge_retained则与之相反,意味着ARC将交出对象的所有权。若是前面那段代码改用它来实现,那么用完数组之后就要加上CFRelease(aCFArray)以释放其内存。与之相似,反向转换可通过bridge_transfer来实现。比方说,想把CFArrayRef转换为NSArray*,并且想令ARC获得对象所有权,那么就可以采用此种转换方式。这三种转换方式成为“桥式转换”(bridged cast)。
以纯Objective-C来编写应用程序时,为何要用到这种功能呢?这是因为:Foundation框架中的Objective-C类所具备的某些功能,是CoreFoundation框架中的C语言数据结构所不具备的,反之亦然。在使用Foundation框架中的字典对象时会遇到一个大问题,那就是其键的内存管理语义为”拷贝“,而值的语义却是”保留“。除非使用强大的无缝桥接技术,否则无法改变其语义。
CoreFoundation框架中的字典类型叫做CFDictionary。其可变版本称为CFMutableDictionary。创建CFMutableDictionary时,可以通过下列方法来指定键和值的内存管理语义:1
2
3
4
5
6CFMutableDictionaryRef CFDictionaryCreateMutable(
CFAllocatorRef allocator,
CFIndex capacity,
const CFDictionaryKeyCallBacks *keyCallBacks,
const CFDictionaryValueCallBacks *valueCallBacks
);
首个参数表示将要使用的内存分配器。CoreFoundation对象里的数据结构需要占用内存,而分配器负责分配及回收这些内存。开发者通常为这个参数传入NULL,表示采用默认的分配器。
第二个参数定义了字典的初始化大小。它并不会限制字典的最大容量,只是向分配器提示了一开始应该分配多少内存。加入要创建的字典含有10个对象,那就向该参数传入10。
最后两个参数值得注意。它们定义了许多回调函数,用于指示字典中的键和值在遇到各种事件时应该执行何种操作。这两个参数都是指向结构体的指针,二者所对应的结构体如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15struct CFDictionaryKeyCallBacks{
CFIndex version;
CFDictionaryRetainCallBack retain;
CFDictionaryReleaseCallBack release;
CFDictionaryCopyDescriptionCallBack copyDescription;
CFDictionaryEqualCallBack equal;
CFDictionaryHashCallBack hash;
};
struct CFDictionaryValueCallBacks{
CFIndex version;
CFDictionaryRetainCallBack retain;
CFDictionaryReleaseCallBack release;
CFDictionaryCopyDescriptionCallBack copyDescription;
CFDictionaryEqualCallBack equal;
};
version参数目前应设为0。当前编程时总是取这个值,不过将来苹果公司也许会修改此结构体,所以要预留该值以表示版本号。这个参数可以用于检测新版与旧版数据结构之间是否兼容。结构体中的其余成员都是函数指针,它们定义了各种事件发生时应该采用哪个函数来执行相关任务。比方说,如果字典中加入了新的键与值,那么就会调用retain函数。此参数的类型定义如下:1
2
3
4typedef const void * (*CFDictionaryRetainCallBack) (
CFAllocatorRef allocator,
const void *value
);
由此可见retain是个函数指针,其所指向的函数接受两个参数,其类型分别是CFAllocatorRef与const void 。传给此函数的value参数表示即将加入字典中的键或值。而返回的void则表示要加到字典里的最终值。开发者可以用下列代码实现这个回调函数:1
2
3
4const void * CustomCallback(CFAllocatorRef allocator,const void *value)
{
return value;
}
这么写只是把将加入字典中的值照原样返回。于是,如果用它充当retain回调函数来创建字典,那么该字典就不会“保留”键与值了。将此种写法与无缝桥接搭配起来,就可以创建出特殊的NSDictionary对象,而其行为与用Objective-C创建出来的普通字典不同。
下面的代码演示了这种字典的创建步骤:
#import <Foundation/Foundation.h>
#import <CoreFoundation/CoreFoundation.h>
const void* EOCRetainCallback(CFAllocatorRef allocator, const void *value)
{
return value;
}
void EOCReleaseCallback(CFAllocatorRef allocator, const void *value)
{
CFRelease(value);
}
CFDictionaryKeyCallBacks keyCallbacks = {
0,
EOCRetainCallback,
EOCReleaseCallback,
NULL,
CFEqual,
CFHash
};
CFDictionaryValueCallBacks valueCallbacks = {
0,
EOCRetainCallback,
EOCReleaseCallback,
NULL,
CFEqual
};
CFMutableDictionaryRef aCFDictionary = CFDictionaryCreateMutable(NULL, 0, &keyCallbacks,&valueCallbacks);
NSMutableDictionary *anNSDictinary = (__bridge_transfer NSMutableDictionary *)aCFDictionary;
在设定回调函数时,copyDescription取值为NULL,因为采用默认实现就很好,而equal与hash回调函数分别设为CFEqual与CFHash,因为这二者所采用的做法与NSMutableDictionary的默认实现相。CFEqual最终会调用NSObject的“isEqual:”方法,而CFHash则会调用hash方法。由此可以看出无缝桥接技术更为强大的一面。
键与值所对应的retain与release回调函数指针分别指向EOCRetainCallback与EOCReleaseCallback函数。如果用作键的对象不支持拷贝操作,此时就不能使用普通的NSMutableDictionary了,因为对象所属的类不支持NSCopying协议,因为“copyWithZone:”方法未实现。开发者可以直接在CoreFoundation层创建字典,于是就能修改内存管理语义,对键执行“保留”而非“拷贝”操作了。
- 要点:
- 通过无缝桥接技术,可以在Foundation框架中的Objective-C对象与CoreFoundation框架中的C语言数据结构之间来回转换。
- 在CoreFoundation层面创建collection时,可以指定许多回调函数,这些函数表示此collection应如何处理器元素。然后,可运用无缝桥接技术,将其转换成具备特殊内存管理语义的Objective-C collection。
50. 构建缓存时,使用NSCache而非NSDictionary
NSCache是Foundation框架专为处理缓存任务而设计的。
- NSCache胜过NSDictionary之处在于:
当系统资源将要耗尽时,它可以自动删减缓存。如果采用普通的字典,那么就要自己编写挂钩,在系统发出“低内存”(low memory)通知时手工删减缓存。而NSCache则会自动删减,由于其是NSFoundation框架的一部分,所以与开发者相比,它能在更深的层面上插入挂钩。NSCache还会先行删减”最久未使用的”对象。若想自己编写代码来为字典添加此功能,则会十分复杂。NSCache并不会“拷贝”键,而是会“保留”它。此行为用NSDictionary也可以实现,然而需要编写相当复杂的代码。NSCache对象不拷贝键的原因在于:很多时候,键都是由不支持拷贝操作的对象来充当的。因此,NSCache不会自动拷贝键,所以说,在键不支持拷贝操作的情况下,该类用起来比字典更方便。NSCache是线程安全的。而NSDictionary则绝对不具备此优势,意思就是:在开发者自己不编写加锁代码的前提下,多个线程便可以同时访问NSCache。对缓存来说,线程安全通常很重要,因为开发者可能要在某个线程中读取数据,此时如果发现缓存里找不到指定的键,那么就要下载该键所对应的数据了。而下载完数据之后所要执行的回调函数,有可能会放在背景线程中运行,这样的话,就等于是用另外一个线程来写入缓存了。
开发者可以操控缓存删减其内容的时机。有两个与系统资源相关的尺度可供调整,其一是缓存中的对象总数,其二是所有对象的”总开销”。开发者在将对象加入缓存时,可为其指定”开销值“。当对象总数或总开销超过上限时,缓存就可能会删减其中的对象了,在可用的系统资源趋于紧张时,也会这么做。然而要注意,是”可能“会删减某个对象,而不是”一定“会删减某个对象。删减对象时所遵照的顺序,由具体实现来定。
向缓存中添加对象时,只有在能很快计算出”开销值”的情况下,才应该考虑采用这个尺度。若计算过程很复杂,那么照这种方式来使用缓存就达不到最佳效果了。
下面演示了缓存的用法:
//Network fetcher class
typedef void(^EOCNetworkFetcherCompletionHandler) (NSData *data);
@interface EOCNetworkFetcher : NSObject
-(instancetype)initWithURL:(NSURL *)url;
-(void)startWithCompletionHandler:(EOCNetworkFetcherCompletionHandler)handler;
@end
@interface CacheTest()
{
NSCache *_cache;
}
@end
@implementation CacheTest
-(instancetype)init{
if(self = [super init]){
_cache = [NSCache new];
//Cache a maximum of 100 URLs
_cache.countLimit = 100;
//The size in bytes of data is used as the cost
_cache.totalCostLimit = 5*1025*1024;//5MB
}
return self;
}
-(void)downloadDataForURL:(NSURL *)url{
NSData *cachedData = [_cache objectForKey:url];
if(cachedData){
//Cache hit
[self useData:cachedData];
}else{
//Cache miss
EOCNetworkFetcher *fetcher = [[EOCNetworkFetcher alloc]initWithURL:url];
[fetcher startWithCompletionHandler:^(NSData *data) {
[_cache setObject:data forKey:url cost:data.length];
[self useData:data];
}];
}
}
@end
本例中,下载数据所用的URL,就是缓存的键。若缓存未命中,则下载数据并将其放入缓存。而数据的开销值则为其长度。创建NSCache时,将其中可缓存的总对象数目上限设为100,将总开销上限设置为5MB。
还有个类叫NSPurgeableData,和NSCache搭配起来用,效果很好,此类是NSMutableData的子类,而且实现了NSDiscardableContent协议。如果某个对象所占的内存能够根据需要随时丢弃,那么就可以实现该协议所定义的接口。这就是说,当系统资源紧张时,可以把保存NSPurgeableData对象的那块内存释放掉。NSDiscardableContent协议里定义了名为isContentDiscarded的方法,可用来查询相关内存是否已释放。
如果需要访问某个NSPurgeableData对象,可以调用其beginContentAccess方法,告诉它现在还不应丢弃自己所占的内存。用完之后,调用endContentAccess方法,告诉它在必要时可以丢弃自己所占的内存了。这些调用可以嵌套,所以说,它们就像递增与递减引用计数所用的方法那样。只有对象的”引用计数“为0时才可以丢弃。
如果将NSPurgeableData对象加入NSCache,那么当该对象为系统所丢弃时,也会自动从缓存中移除。通过NSCache的evictsObjectsWithDiscardedContent属性,可以开启或关闭此功能。
刚才那个例子可以用NSPurgeableData改写如下:
-(void)downloadDataForURL:(NSURL *)url{
NSPurgeableData *cachedData = [_cache objectForKey:url];
if(cachedData){
//Stop the data being purged
[cachedData beginContentAccess];
//Use the cached data
[self useData:cachedData];
//Mark that the data may be purged again
[cachedData endContentAccess];
}else{
//Cache miss
EOCNetworkFetcher *fetcher = [[EOCNetworkFetcher alloc]initWithURL:url];
[fetcher startWithCompletionHandler:^(NSData *data) {
NSPurgeableData *purgeableData = [NSPurgeableData dataWithData:data];
[_cache setObject:purgeableData forKey:url cost:data.length];
//Don't need to beginContentAccess as it begins
//with access already marked
//Use the retrieved data
[self useData:data];
//Mark that the data may be purged now
[purgeableData endContentAccess];
}];
}
}
注意,创建好NSPurgeableData对象之后,其”purge引用计数“会多1,所以无须再调用beginContentAccess了,然而气候必须调用endContentAccess,将多出来的这个”1“抵消掉。
- 要点:
- 实现缓存时应选用NSCache而非NSDictionary对象。因为NSCache可以提供优雅的自动删减功能,而且是“线程安全的”,此外,它与字典不同,并不会拷贝键。
- 可以给NSCache对象设置上限,用以限制缓存中的对象总个数及“总成本“,而这些尺度则定义了缓存删减其中对象的时机。但是绝对不要把这些尺度当成可靠的”硬限制“(hard limit),它们仅对NSCache起指导作用。
- 将NSPurgeableData于NSCache搭配使用,可实现自动清除数据的功能,也就是说,当NSPurgeableData对象所占内存为系统所丢弃时,该对象自身也会从缓存中移除。
- 如果缓存使用得当,那么应用程序的响应速度就能提高。只有那种”重新计算起来很费事的“数据,才值得放入缓存,比如那些需要从网络获取或从磁盘读取的数据。
51. 精简initialize与load的实现代码
有时候,类必须先执行某些初始化操作,然后才能正常使用。NSObject类有两个方法,可用来实现这种初始化操作。
load方法原型:1
+ (void)load;
对于加入运行期系统中的每个类及分类来说,必定会调用此方法,而且仅调用一次。当包含类或分类的程序库载入系统时,就会执行此方法,而这通常就是指应用程序启动的时候,若程序是为iOS平台设计的,则肯定会在此时执行。Mac OS X应用程序更自由一些,它们可以使用”动态加载“之类的特性,等应用程序启动好之后再去加载程序库。如果分类和其他所属的类都定义了load方法,则先调用类里的,再调用分类里的。
load方法的问题在于,执行该方法时,运行期系统处于”脆弱状态”。在执行子类的load方法之前,必定会先执行所有超类的load方法,而如果代码还依赖了其他程序库,那么程序库里相关类的load方法也必定会先执行。然而,根据某个给定的程序库,却无法判断出其中各个类的载入顺序。因此,在load方法中使用其他类是不安全的。
比方说:
#import <Foundation/Foundation.h>
#import "EOCClassA.h"// From the same library
@interface EOCClassB : NSObject
@end
@implementation EOCClassB
+(void)load {
NSLog(@"Loading EOCClassB");
EOCClassA *object = [EOCClassA new];
//Use 'object'
}
@end
此处使用NSLog没问题,而且相关字符串也会照常记录,因为Foundation框架肯定在运行load方法之前就已经载入系统了。但是,在EOCClassB的load方法里使用EOCClassA却不太安全,因为无法确定在执行EOCClassB的load方法之前,EOCClassA是不是已经记载好了。可以想见:EOCClassA这个类,也许会在其load方法中执行某些重要操作,只有执行完这些操作之后,该类实例才能正常使用。
- load方法并不像普通的方法那样,它并不遵从那套继承规则,如果某个类本身没实现load方法,那么不管其各级超类是否实现此方法,系统都不会调用。此外,分类和其所属的类里,都可能出现load方法。此时两种实现代码都会调用,类的实现要比分类的实现先执行。
- load方法务必实现得精简一些,也就是要尽量减少其所执行的操作,因为整个应用程序在执行load方法时都会阻塞。如果load方法中包含繁杂的代码,那么应用程序在执行期间就会变得无响应。不要在里面等待锁,也不要调用可能会加锁的方法。总之,能不做的事情就别做。
想执行与类相关的初始化操作,还有个办法,就是覆写下列方法:1
+ (void)initialize;
对于每个类来说,该方法会在程序首次用该类之前调用,且只调用一次。它是由运行期系统来调用的,绝不应该通过代码直接调用。其虽与load相似,但却有几个非常重要的微妙区别。首先,它是”惰性调用的”,也就是说,只有当程序用到了相关的类时,才会调用。因此,如果某个类一直都没有使用,那么其initialize方法就一直不会运行。这也就是说,应用程序无须先把每个类的initialize都执行一遍,这与load方法不同,对于load来说,应用程序必须则色并等着所有类的load都执行完,才能继续。
此方法与load还有个区别,就是运行期系统在执行该方法时,是处于正常状态的,因此,从运行期系统完整度上来讲,此时可以安全使用并调用任意类中的任意方法。而且,运行期系统也能保证initialize方法一定会在”线程安全的环境“中执行,这就是说,只有执行initialize的那个线程可以操作类或类的实例。其他线程都要先则色,等着initialize执行完。
最后一个区别是:initialize方法与其他消息一样,如果某个类未实现它,而其超类实现了,那么就会运行超类的实现代码。
initialize也遵循通常的继承规则,通常都会这么来实现initialize方法:1
2
3
4
5
6
7+(void)initialize
{
if(self = [EOCBaseClass class])
{
NSLog(@"%@ initialized",self);
}
}
加上这条检测语句之后,只有当开发者所期望的那个类载入系统时,才会执行相关的初始化操作。
在load和initialize方法中尽量精简代码,在里面设置一些状态,使本类能够正常运作就可以了,不要执行那种耗时太久或需要加锁的任务。
开发者无法控制类的初始化时机。类在首次使用之前,肯定要初始化,但编写程序时不能令代码依赖特定的时间点,否则会很危险。运行期系统将来更新了之后,可能会略微改变类的初始化方式,这样的话,开发者原来如果假设某个类必定会在某个具体时间点初始化,那么现在这条假设可能就不成立了。
如果某个类的实现代码很复杂,那么其中可能会直接或间接用到其他类。若那些类尚未初始化,则系统会迫使其初始化。然而,本类的初始化方法此时尚未运行完毕。其他类在运行其initialize方法时,有可能会依赖本类中的某些数据,而这些数据此时也许还未初始化好。
若某个全局状态无法在编译期初始化,则可以在initialize里来做:
#import "EOCClass.h"
static const int kInterval = 10;
static NSMutableArray *kSomeObjects;
+(void)initialize {
if(self = [EOCClass class]) {
kSomeObjects = [NSMutableArray new];
}
}
- 要点:
- 在加载阶段,如果类实现了load方法,那么系统就会调用它。分类里也可以定义此方法,类的load方法要比分类中的先调用。与其他方法不同,load方法不参与覆写机制。
- 首次使用某个类之前,系统会向其发送initialize消息。由于此方法遵从普通的覆写规则,所以通常应该在里面判断当前要初始化的是哪个类。
- load与initialize方法都应该实现得精简一些,这有助于保持应用程序的响应能力,也能减少引入”依赖环“(interdependency cycle)的几率。
- 无法在编译器设定的全局变量,可以放在initialize方法里初始化。
52. 别忘了NSTimer会保留其目标对象
计时器要和“运行循环”(run loop)相关联,运行循环到时候会触发任务。创建NSTimer时,可以将其“预先安排”在当前的运行循环中,也可以先创建好,然后由开发者自己来调度。无论采用哪种方式,只有把计时器放在运行循环里,它才能正常触发任务。
例如下面这个方法可以创建计时器,并将其预先安排在当前运行循环中:1
+ (NSTimer *)timerWithTimeInterval:(NSTimeInterval)timeInterval target:(id)aTarget selector:(SEL)aSelector userInfo:(nullable id)userInfo repeats:(BOOL)yesOrNo;
用“块”来打破保留环:
#import <Foundation/Foundation.h>
@interface NSTimer (EOCBlocksSupport)
+ (NSTimer *)eoc_timerScheduledTimerWithTimeInterval:(NSTimeInterval)interval block:(void(^)())block repeats:(BOOL)repeats;
@end
.
#import "NSTimer+EOCBlocksSupport.h"
@implementation NSTimer (EOCBlocksSupport)
+ (NSTimer *)eoc_timerScheduledTimerWithTimeInterval:(NSTimeInterval)interval block:(void(^)())block repeats:(BOOL)repeats {
return [self scheduledTimerWithTimeInterval:interval target:self selector:@selector(eoc_blockInvoke:) userInfo:[block copy] repeats:repeats];
}
+ (void)eoc_blockInvoke:(NSTimer *)timer {
void (^block) () = timer.userInfo;
if (block) {
block();
}
}
@end
1 | -(void)startPolling { |
- 要点:
- NSTimer对象会保留其目标,直到计时器本身失效为止,调用invalidate方法可令计时器失效,另外,一次性的计时器在触发完任务之后也会失效。
- 反复执行任务的计时器,很容易引入保留环,如果这种计时器的目标对象又保留了计时器本身,那肯定会导致保留环。这种环状保留关系,可能是直接发生的,也可能是通过对象图里的其他对象间接发生的。
- 可以扩充NSTimer的功能,用“块”来打破保留环。不过,除非NSTimer将来在公共接口里提供此功能,否则必须创建分类,将相关实现代码加入其中。